データパイプラインとは?データを自動で運び、使える形に整える仕組み
データパイプラインとは、データを発生源から利用先まで自動で運び、途中で使える形に加工する処理の連なり です。パイプライン(pipeline)は本来「配管」を意味する言葉で、水道管の中を水が流れるように、データが処理から処理へと自動で流れていく様子を表しています。
対になるイメージは「人手によるバケツリレー」です。担当者が管理画面からCSVをダウンロードし、Excelで整形し、共有フォルダに置く——この手作業の連鎖をソフトウェアによる自動の流れに置き換えたものが、データパイプラインだと考えてください。
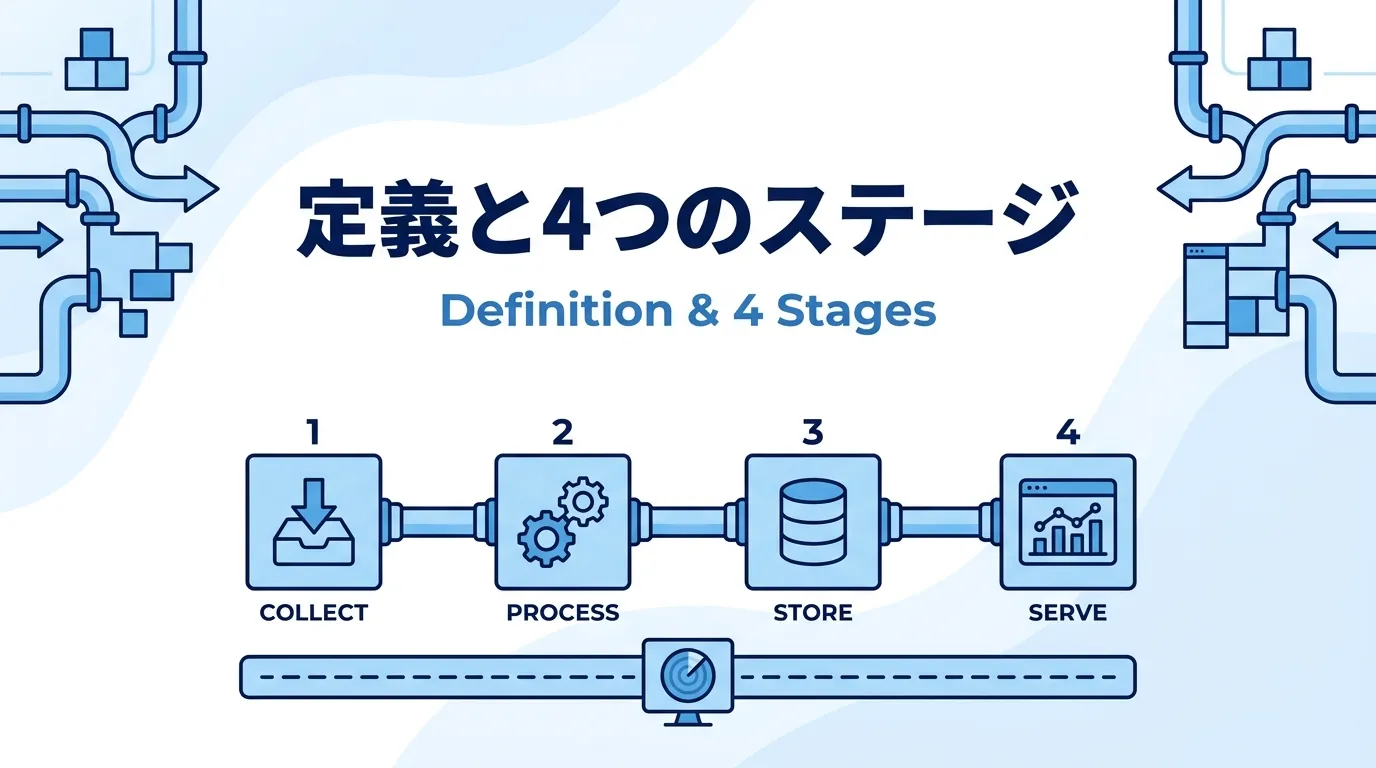
データパイプラインを構成する4つのステージ データパイプラインは、おおむね「収集・処理・蓄積・提供」の4つのステージで構成されます。次の図のように、データは左から右へ流れ、その全体を下段のオーケストレーション・監視が支える構造です。
データソースSaaS / DB / ログ
→
収集抽出・転送
→
処理変換・クレンジング
→
蓄積DWH / データレイク
→
提供BI / ML / 業務システム
オーケストレーション・監視(実行順序の制御/失敗の検知/リトライ)
データパイプラインの4つのステージ。全体をオーケストレーション・監視が下支えする 収集 :SaaS・業務データベース・アプリのログなどから、データを抽出して運び出す処理 :型変換・表記揺れの統一・集計など、分析に使える形への加工を行う蓄積 :DWH(データウェアハウス。分析用にデータを集約するデータベース)やデータレイク(生データを加工せず安価に貯めておく置き場)に格納する提供 :BIツールでの可視化、機械学習モデル、業務システムなど、利用先へデータを届ける図の下段にあるオーケストレーション・監視は、4つのステージそのものではなく「ステージ全体を毎日正しく動かし続けるための土台」です。この土台こそがパイプライン運用の肝になるため、後半の章で詳しく扱います。
データ基盤全体の中でパイプラインが占める位置 データ基盤(データの収集・蓄積・分析を担う社内のインフラ全体)にあてはめると、パイプラインはデータソースとDWHをつなぐ動脈にあたります。
データソース
パイプライン
DWH
データマート
BIツール
SalesforceCRM
GA4広告管理
基幹システムERP
IoT・センサー
BIツールTableau / Looker / Power BI
図のとおり、どれだけ高性能なDWHやBIツールを揃えても、パイプラインが止まればデータは1行も届きません。冒頭の「数字が3日前のまま」という症状は、たいていこの動脈のどこかが詰まっています。
データ基盤そのものの考え方や構成要素は、データ基盤とは?企業が導入すべき3つの理由と構成要素を解説 で詳しく解説しています。
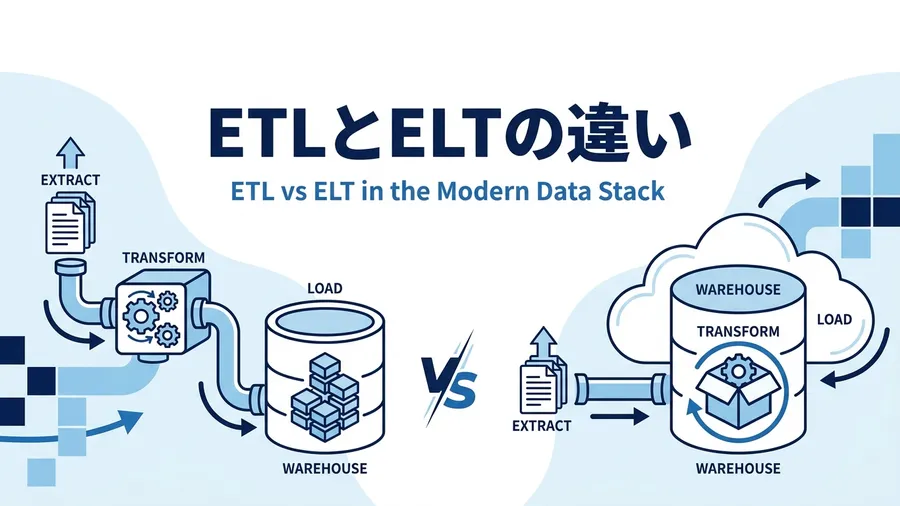
データパイプラインとETLパイプラインの違いは「概念の広さ」
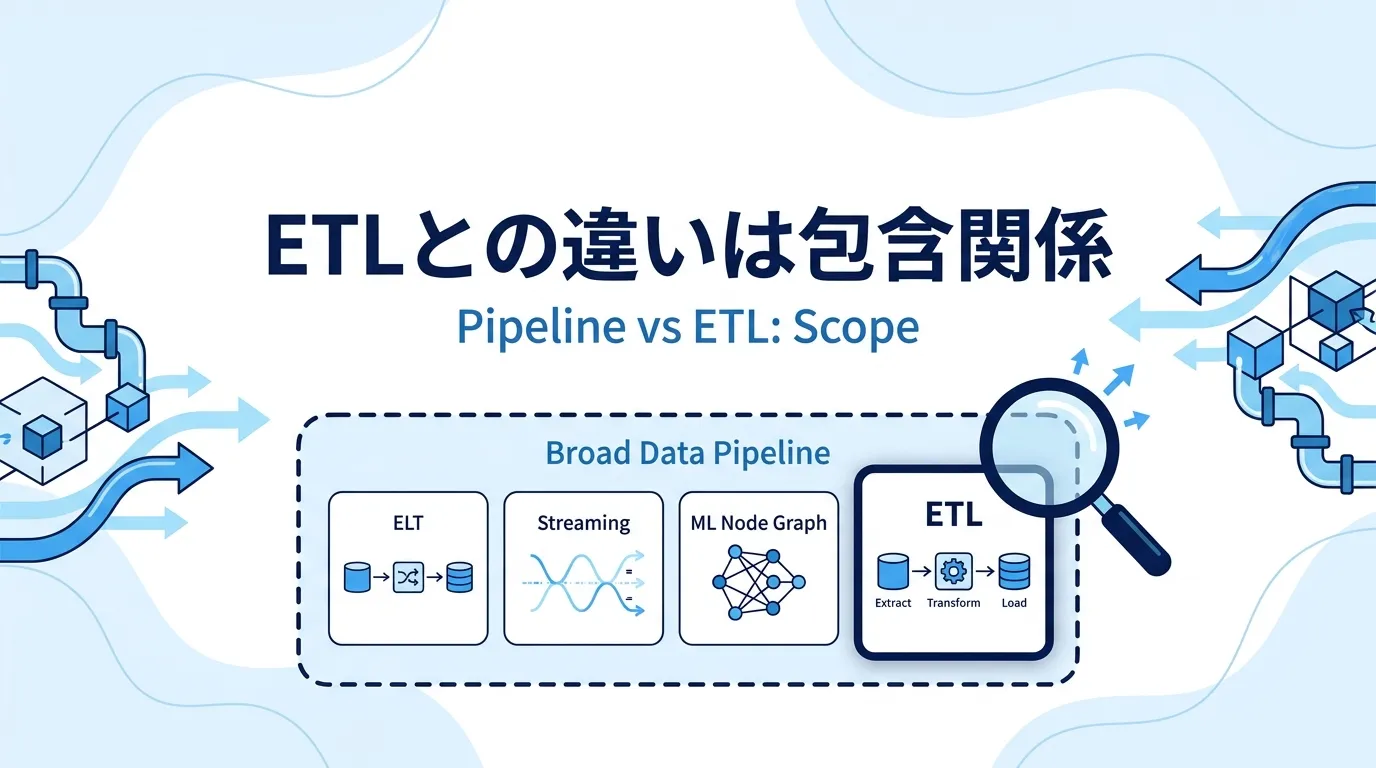
両者の違いは、ひとことで言えば「指している範囲の広さ」です。データパイプラインが「データを自動で運び・加工する処理全般」を指す総称であるのに対し、ETLパイプラインはそのうち「Extract(抽出)→ Transform(変換)→ Load(格納)の順で処理するタイプ 」を指します。
次の図のように、ETLパイプラインはデータパイプラインという大きな枠の中の1区画です。「どちらを使うべきか」という二者択一の関係ではありません。
データパイプライン(データを自動で運び・加工する処理の総称)
ETLパイプライン抽出 → 変換 → 格納の順で処理
ELTパイプラインDWHに入れてから変換
ストリーミング発生の都度リアルタイム処理
ML向け特徴量パイプライン機械学習用の前処理
ETLパイプラインは、データパイプラインという広い概念の中の代表的な一種 観点ごとに整理すると、次のようになります。なお、これは対等な二者の比較ではなく、右の列(ETLパイプライン)は左の列(データパイプライン)に含まれる関係です。
観点 データパイプライン ETLパイプライン 概念の範囲 総称(広義) 一種(狭義) 変換処理 あってもなくてもよい(単純コピーも含む) 必ず含む(Transformが中核) 処理方式 バッチもストリーミングも含む 定期実行のバッチ処理が中心 典型例 ログのリアルタイム集約、ML向け前処理、リバースETL等 基幹システム → DWHの日次バッチ連携
誤解されやすいのは「変換処理」の行です。たとえば業務システムのログをAmazon S3へ毎晩そのままコピーするだけの仕組みは、変換を含まないためETLとは呼べませんが、立派なデータパイプラインです。
ETLの3工程それぞれの仕組みや代表的なツールは、ETLとは?データ統合の基礎と選定ポイントを解説 で図解つきで詳しく扱っています。
なぜ混同されやすいのか:かつては「パイプライン ≒ ETL」だった 2000年代まで、分析目的のデータ連携といえば「夜間のETLバッチ」が中心で、パイプラインといえばETLを指す時代が長く続きました。混同が多いのはこの歴史の名残です。
状況を変えたのが、2010年代のクラウドDWHの普及です。変換をDWH内で行うELT(Extract → Load → Transformの順で処理する方式)が台頭し、IoTやWeb行動ログのリアルタイム処理も一般化しました。
ETLという言葉では捉えきれない多様な形が生まれた結果、それらを総称する言葉として「データパイプライン」が定着した、という経緯です。
データパイプラインの主要パターン:「処理タイミング」と「変換の場所」の2軸で分類する
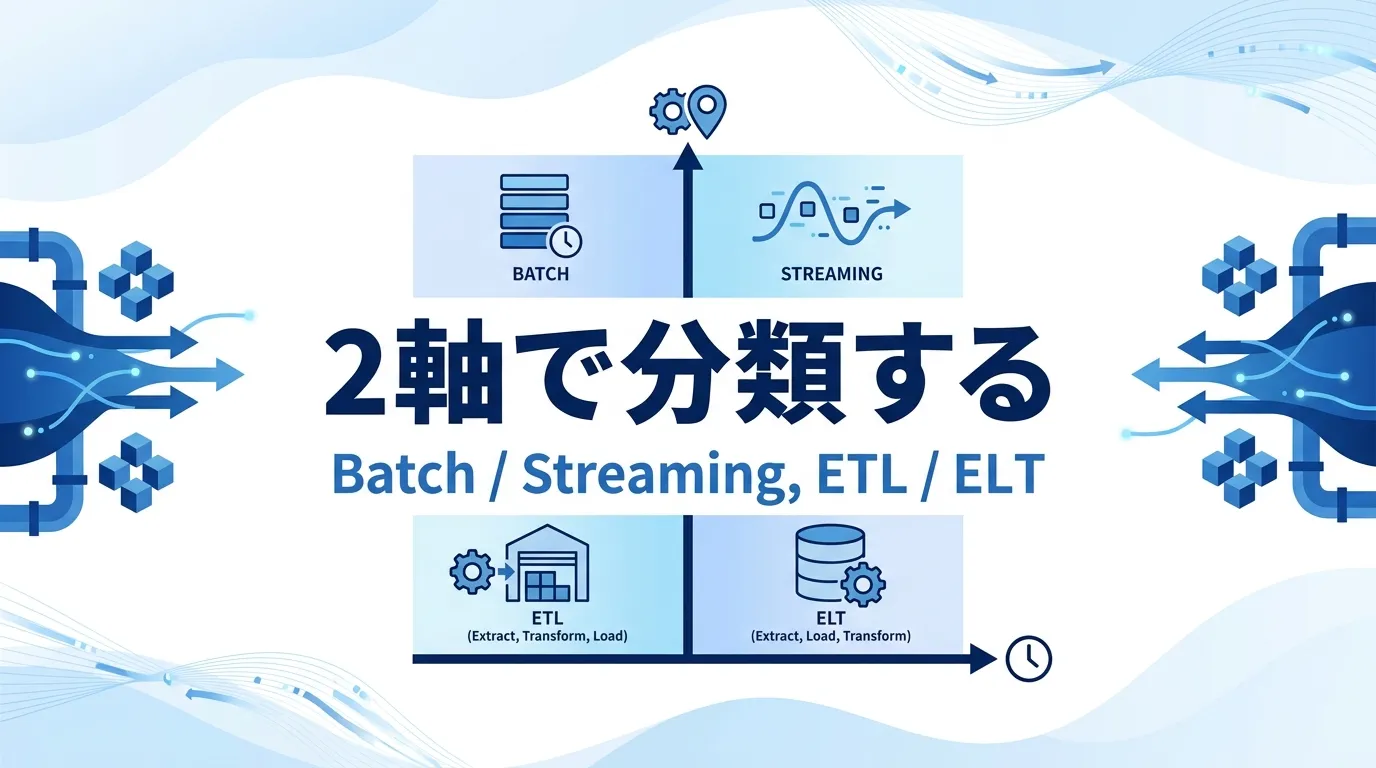
データパイプラインの分類軸はいくつかありますが、実務の設計判断に直結するのは「いつ処理するか(処理タイミング) 」と「どこで変換するか(変換の場所) 」の2つです。前者はバッチかストリーミングか、後者はETLかELTかという選択にあたります。
この2軸は独立しているため、たとえば「バッチ×ELT」「ストリーミング×ETL」のように掛け合わせて考えられます。順に見ていきましょう。
【分類軸1】処理タイミング:バッチ処理かストリーミング処理か バッチ処理は、1日1回や1時間に1回など、決まった間隔でデータをまとめて処理する方式です。日次の売上レポートやKPI集計のように「翌朝までに昨日分が見えればよい」用途では今も主流で、仕組みがシンプルなぶん開発・運用コストを抑えられます。
一方のストリーミング処理は、データが発生するたびに数秒〜数分以内で処理し続ける方式です。ECサイトの不正検知や工場センサーの異常検知など、データの鮮度がそのまま価値になる用途で使われます。Apache KafkaやGoogle Cloud Pub/Sub、Amazon Kinesisといった基盤が代表的ですが、バッチに比べて設計・運用の難易度は一段上がります。
迷ったら、まずバッチから始めるのが定石です。Evastの現場でも「リアルタイムで見たい」という初期要望を要件まで掘り下げると、実際には1時間ごとのバッチで十分だった、というケースが大半を占めます。
【分類軸2】変換の場所:ETL型かELT型か 変換をDWHに入れる前にETLツール側で行うのがETL型、生データを先にDWHへ入れてからSQLで変換するのがELT型です。BigQueryやSnowflakeといったクラウドDWHを使う構成では、DWHの計算能力を活かせるELT型が主流になっています。
どちらを選ぶかは、データ量・セキュリティ要件・分析要件の変化頻度などで判断が分かれます。5つの比較軸と選び方の判断基準は、ETLとELTの違いとは?5つの比較軸とELTが主流になった理由 にまとめています。
補足:リバースETLなど用途に特化した派生パターンもある 2軸の組み合わせの上に乗る応用形として、覚えておきたい派生が2つあります。
ML向け特徴量パイプライン :機械学習モデルに入力する変数(特徴量)を生データから作り出す前処理の流れリバースETL :DWHに集めた分析結果を、Salesforceなどの業務システム側へ書き戻す逆方向の流れいずれも「データを自動で運び・加工する」という本質は同じで、データパイプラインの一種です。
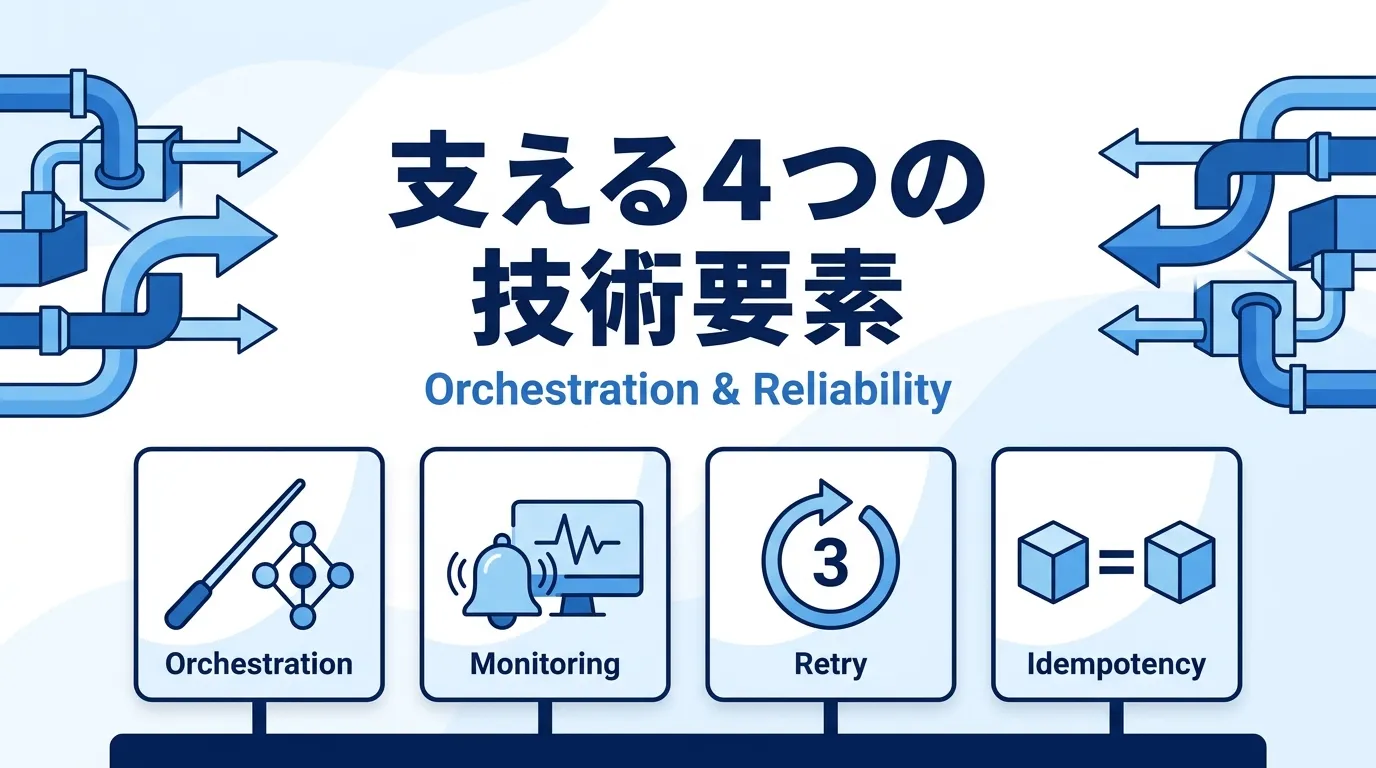
データパイプラインを支える4つの技術要素:オーケストレーション・監視・リトライ・冪等性
パイプラインは「作って終わり」ではなく「毎日動かし続ける」ものです。Evastのプロジェクトでも、工数の感覚としては初期構築が3割、安定運用の仕組みづくりが7割という配分になることが珍しくありません。
動かし続けるために押さえるべき技術要素は、次の4つです。
【技術要素1】オーケストレーション:Airflowなどで実行順序と依存関係を一元管理する オーケストレーション(複数の処理を正しい順序・タイミングで実行するよう指揮する仕組み)は、パイプライン運用の中枢です。「売上データの取り込みが終わってから集計を始める」といった依存関係をDAG(有向非巡回グラフ。処理同士の順序関係を表す図)として定義すると、ツールが実行順序を自動で制御してくれます。
代表的なツールは、2015年にAirbnb社がオープンソース化した Apache Airflow です。事実上の標準として広く使われており、Google CloudのCloud Composer、AWSのAmazon MWAAなど、Airflowをマネージドサービス(運用をクラウド側に任せられる提供形態)として使える選択肢も揃っています。後発のオープンソースであるDagsterやPrefectは、開発のしやすさやテスト機能を強みに採用が増えています。Airflow・Dagster・Prefectの設計思想の違いと選び方はAirflow・Dagster・Prefect比較:データパイプラインのオーケストレーションツール選び方 で詳しく整理しています。
OS標準のスケジューラであるcron(決まった時刻にコマンドを実行する仕組み)との違いは、「依存関係を知っているかどうか」です。cronは時刻しか管理できないため、前段の処理が失敗していても後段が平然と動いてしまいます。
【技術要素2】監視:パイプラインが「止まったこと」「データが古いこと」に即座に気づく 監視の基本は、次の3点セットです。
失敗の通知 :ジョブが失敗したら、Slackやメールに即時に知らせる処理時間の監視 :普段20分の処理が2時間かかっていれば異常とみなすデータ鮮度のチェック :最終更新が24時間以上前なら警告を出すとくに見落とされがちなのがデータ鮮度です。パイプラインが止まってもダッシュボード自体は古いデータで表示され続けるため、「画面は出ているのに中身が止まっている」状態に気づけません。
ジョブの成否だけでなく、データそのものの状態を検査する仕組みを入れておくと安心です。dbt(SQLでデータ変換を開発・管理するツール)のテストやsource freshness(鮮度チェック)機能が代表的で、詳しくはdbtとは?BigQueryのデータ変換を効率化するツールを解説 で扱っています。
【技術要素3】エラー処理とリトライ:一時的な失敗は自動で再実行する リトライ(失敗した処理の自動再実行)は、運用負荷を下げる基本装備です。連携先APIのタイムアウトやネットワークの瞬断といった一時的なエラーは、「5分間隔で最大3回」のように間隔をあけて再実行するだけで成功することが多いためです。
Airflowなどのオーケストレーションツールでは、タスク単位でリトライ回数と間隔を設定できます。一方、連携元のレイアウト変更のような恒久的なエラーはリトライでは直らないため、規定回数で打ち切って人に通知する設計が必要です。
【技術要素4】冪等性:同じ処理を2回実行しても結果が変わらないように作る 冪等性(べきとうせい。同じ処理を何度実行しても結果が同じになる性質)は、リトライや手動再実行を安全にするための前提条件です。
たとえば追記(INSERT)だけで作られたパイプラインを再実行すると、同じデータが二重に取り込まれます。対象日のデータをいったん削除してから入れ直す「洗い替え」や、キーが一致すれば更新・なければ挿入するMERGE(Upsert)処理を使えば、何度実行しても結果は同じに保てます。
リトライ(技術要素3)を安心して使えるのは、冪等性が確保されているからこそです。4つの要素は独立した部品ではなく、互いに支え合う関係にあります。
データパイプライン設計・運用の注意点:Evastの現場で見た3つの失敗
技術要素を押さえていても、設計と運用ルールを誤ると現場は混乱します。私たちが基盤の立て直し支援で実際に遭遇した失敗を、3つ紹介します。
【設計・運用の失敗1】cronとシェルスクリプトの乱立で、誰も全体像を把握できなくなる ある企業では、5年かけて少しずつ増えたcronジョブ(シェルスクリプトの定時起動)が30本を超え、実行順序が「Aは深夜2時、Bは3時開始だから間に合うはず」という暗黙の時刻調整だけで保たれていました。データ量の増加でAの処理が3時を超えるようになった途端、後続が連鎖的に欠損し、原因特定に数日を要しました。
ジョブ間の依存関係が誰の頭の中にもない状態は、担当者の異動・退職で一気にブラックボックス化します。ジョブが10本を超えたあたりで、オーケストレーションツールへの移行と依存関係のコード化を検討してください。
【設計・運用の失敗2】パイプラインの失敗に1週間誰も気づかない「サイレント障害」 通知を仕込んでいない、あるいは通知が多すぎて誰も見なくなっている——どちらのパターンでも、結果は「気づかれない障害」です。前述のとおりダッシュボードは古いデータのまま表示され続けるため、経営会議の場で「この数字、先週から動いていなくないか」と指摘されて初めて発覚した例もあります。
対策はシンプルで、失敗通知とデータ鮮度監視を最初から組み込み、通知は「人が必ず見るチャンネル1つ」に絞ることです。通知の乱発はオオカミ少年化を招くため、警告レベルの整理も合わせて行いましょう。
【設計・運用の失敗3】障害復旧の再実行で、売上データが二重計上される 障害からの復旧時にバッチを手動で再実行したところ、その日の売上データが二重に取り込まれ、翌月のレポートの数字が合わないことで発覚した——冪等性を後回しにした典型的な失敗です。信頼を一度失ったダッシュボードは、数字が直った後もなかなか使ってもらえません。
「このパイプラインは再実行しても安全か?」を設計レビューの必須観点に加え、洗い替えやMERGEを標準パターンとして整備しておくことが予防策になります。
まとめ:広い概念としてのパイプラインを理解し、運用まで設計する
データパイプラインの定義からETLパイプラインとの違い、運用の要点までを整理しました。要点は次の5つです。
データパイプラインとは :データを発生源から利用先まで自動で運び・加工する処理の連なりETLとの違い :対立ではなく包含関係。ETLパイプラインはデータパイプラインの代表的な一種構成 :収集 → 処理 → 蓄積 → 提供の4ステージと、それを支えるオーケストレーション・監視分類 :処理タイミング(バッチ/ストリーミング)と変換の場所(ETL/ELT)の2軸で整理できる運用 :監視・リトライ・冪等性は後付けではなく、設計段階から組み込むパイプラインは作った瞬間がゴールではなく、毎日動き続けて初めて価値を生みます。ツール選定の前に「止まったとき誰がどう気づき、どう復旧するか」まで描けているかを、ぜひ一度確認してみてください。
データパイプラインの設計・構築のご相談はEvastへ 株式会社Evastでは、データパイプラインの設計からオーケストレーション整備、DWH構築、BIダッシュボード開発まで、一貫したデータ基盤構築 を支援しています。
「手作業のデータ集計を自動化したいが、何から始めるべきかわからない」 「cronジョブが乱立し、データ連携がブラックボックス化している」 「Airflowやdbtを使ったモダンなパイプラインに刷新したい」 このようなお悩みがあれば、お気軽にご相談ください。現状診断からアーキテクチャ設計、運用体制づくりまでを伴走します。
→ データ基盤構築サービスを見る 無料相談を申し込む