「社内のデータが各システムにバラバラで、分析に使えない」「手作業でのデータ集計に毎月40〜60時間もかかっている」——データ活用を進めようとする企業が最初にぶつかる壁が、このデータの分散と統合の問題です。
この課題を解決する技術が ETL です。ETLはデータ基盤を支える最も重要な要素の一つであり、データ活用の成否を左右するといっても過言ではありません。
本記事では、ETLの基本から3つの機能、ELT・EAIとの違い、そしてデータ基盤における役割までを、図解と具体例を交えて徹底解説します。

「社内のデータが各システムにバラバラで、分析に使えない」「手作業でのデータ集計に毎月40〜60時間もかかっている」——データ活用を進めようとする企業が最初にぶつかる壁が、このデータの分散と統合の問題です。
この課題を解決する技術が ETL です。ETLはデータ基盤を支える最も重要な要素の一つであり、データ活用の成否を左右するといっても過言ではありません。
本記事では、ETLの基本から3つの機能、ELT・EAIとの違い、そしてデータ基盤における役割までを、図解と具体例を交えて徹底解説します。

ETLとは、Extract(抽出)・Transform(変換)・Load(書き出し) の頭文字を取った略語です。複数のデータソースからデータを取り出し、分析に適した形に加工して、データウェアハウス(DWH)などに格納する一連のプロセスを指します。
シンプルに言えば、ETLは「バラバラのデータを集めて、使える形に整えて、一箇所にまとめる」仕組みです。
企業のデータは通常、以下のように散在しています。
これらのデータは、フォーマットも文字コードもデータ形式もバラバラです。そのままでは横断的な分析ができません。
ETLは、こうしたデータのサイロ化を解消し、統一されたフォーマットで一箇所に集約する役割を担います。

ETLの各プロセスを、具体的に見ていきましょう。
最初のステップは、複数のデータソースから必要なデータを抽出することです。
対象となるデータソースの例:
抽出時の3つのパターン:
| パターン | 内容 | 主なユースケース |
|---|---|---|
| 全量抽出 | すべてのデータを取得 | 初回ロード時、マスタデータ |
| 差分抽出 | 前回以降に更新されたデータのみ取得 | 日次バッチ等の定常運用 |
| 条件付き抽出 | 特定の条件に合致するデータのみ取得 | 部分的な分析、テスト |
差分抽出を活用することで、処理時間の短縮とシステム負荷の軽減が可能になります。
より高度な差分抽出手法として CDC があります。データベースの変更ログ(トランザクションログ)を監視して、リアルタイムに差分を検出する手法です。Debezium などのツールが代表的で、ニアリアルタイムなデータ連携に活用されています。
抽出したデータを、分析や活用に適した形式に変換します。ETLの中で最も重要なプロセスであり、データ品質を左右します。
代表的な変換処理:
「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」という言葉があるように、データ分析の精度は入力データの品質に依存します。変換プロセスでしっかりとクレンジングを行うことで、信頼性の高い分析結果が得られます。
変換したデータを、データウェアハウス(DWH)やデータマートなどの格納先に書き出します。DWHの仕組みや、データレイク・データマートとの違いについてはDWH(データウェアハウス)とは?データレイク・データマートとの違いを解説で詳しく整理しています。
主な格納先:
| 種類 | 代表例 | 用途 |
|---|---|---|
| データウェアハウス(DWH) | BigQuery、Snowflake、Amazon Redshift | 全社の統合データ |
| データレイク | Amazon S3、Google Cloud Storage、Azure Data Lake | 生データ・半構造化データの保管 |
| データマート | 部門別に最適化されたデータベース | 特定業務向けの分析用 |
書き出しの3つのパターン:

ETLプロセスはプログラミングでも実現できますが、専用ツールを使うことで大きなメリットがあります。
スクラッチ開発では、データソースごとにプログラムを書く必要があります。ETLツールなら、GUIでドラッグ&ドロップするだけで連携処理を構築できます。
開発期間の目安(5システム連携の場合):
| 開発方法 | 期間 | 工数 |
|---|---|---|
| スクラッチ開発 | 約3か月 | 約480時間 |
| ETLツール利用 | 約2週間 | 約80時間 |
→ 工数を約80%削減できる計算になります。
プログラムによる開発は、特定のエンジニアに依存しがちです。ETLツールは処理フローがGUIで可視化されるため、担当者が変わっても引き継ぎが容易です。
ETLツールは定義されたルールに基づいて処理を行うため、ヒューマンエラーを最小限に抑えられます。バリデーション機能やエラーハンドリング機能も標準で充実しています。
これらにより、安定した運用が可能になります。
導入効果の実績例:
ETLツール単体ではなく、ジョブの実行管理・スケジューリングを担うオーケストレーションツール(Apache Airflow、Dagster、Prefect 等)と組み合わせることで、より堅牢なデータパイプラインを構築できます。各ツールの違いと選び方はAirflow・Dagster・Prefect比較:データパイプラインのオーケストレーションツール選び方で解説しています。
これらを使えば、「毎朝6時にETL処理を実行し、9時までに完了させる」といったSLA(サービスレベル)を守る運用が実現できます。
データパイプラインの全体像や、オーケストレーション・監視といった運用の要点は、データパイプラインとは?ETLとの違いと仕組みを図解で解説で詳しく解説しています。

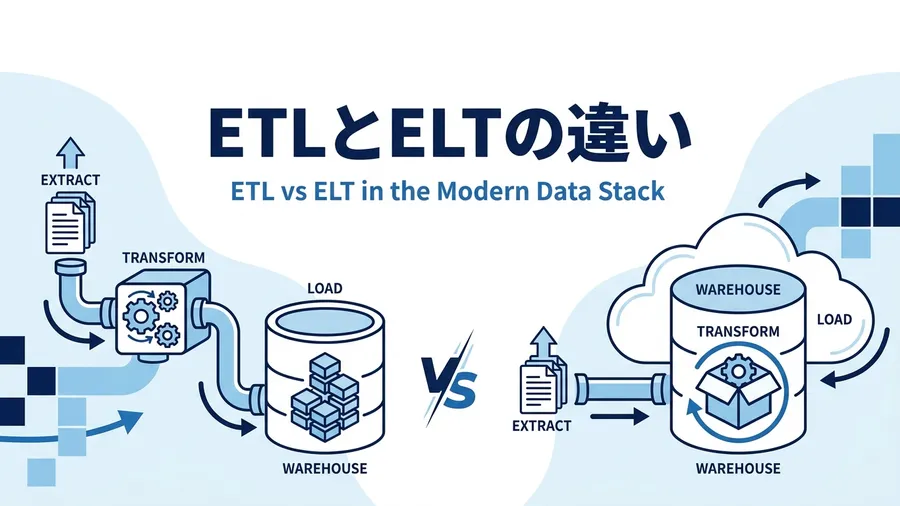
ETLとよく比較されるのが ELT です。ELTは「Extract → Load → Transform」の略で、変換(Transform)と書き出し(Load)の順序が逆になっています。
近年、BigQuery や Snowflake などのクラウドDWHの処理能力が飛躍的に向上しました。これらのDWHは大量データの並列処理が得意なため、変換処理をDWH側で行う「ELT」パターンが主流になりつつあります。ELTが主流になった背景や、両者を5つの軸で比較した選び方の判断基準は、ETLとELTの違いとは?5つの比較軸とELTが主流になった理由で詳しく解説しています。
ELTのメリット:
実際のプロジェクトでは、ETLとELTを組み合わせて使うことが多いです。
このハイブリッドアプローチが、運用性と保守性のバランスを取るうえで効果的です。

もう一つよく混同されるのが EAI(Enterprise Application Integration) です。
| 項目 | ETL | EAI |
|---|---|---|
| 主な目的 | データ分析・蓄積 | システム間連携・業務自動化 |
| 処理タイミング | バッチ処理が中心 | リアルタイムが中心 |
| データの方向 | データソース → DWH(片方向) | システム間の双方向 |
| 代表的ツール | Fivetran、Talend、Airbyte | MuleSoft、Boomi、ASTERIA Warp |
使い分けの指針:
ただし、最近のETLツールはリアルタイム処理にも対応しており、両者の境界は曖昧になりつつあります。

ETLは、データ基盤アーキテクチャの中でどのような位置づけにあるのでしょうか。
ETLは、データソースとDWHを橋渡しする役割を担います。データ基盤の「パイプライン」とも呼ばれ、データの流れを制御する重要なコンポーネントです。そもそもデータ基盤とは何か、導入で何が変わるのかは、データ基盤とは?企業が導入すべき3つの理由と構成要素を解説で詳しく解説しています。
ETLの品質が高いと:
ETLの品質が低いと:
つまり、ETLの設計・実装が、データ基盤全体の価値を左右すると言えます。
現場で頻繁に遭遇するアンチパターンを6つ紹介します。
💡 Evastのデータ基盤構築では:これらの失敗を防ぐため、プロジェクト初期段階で データ定義書・処理フロー図 を整備し、ステージング環境での十分なテスト を経てから本番リリースする体制を徹底しています。

ETLツールを選定する際のポイントを整理します。
自社で使っているシステムに対応しているか確認しましょう。将来的に連携したいシステムも考慮しておくことが重要です。
データ量の増加に耐えられるか、並列処理に対応しているかを確認します。
初期費用だけでなく、運用コスト(ライセンス、インフラ、データ転送量)も含めて評価しましょう。
主要なツールをカテゴリ別に整理します。
| カテゴリ | ツール | 特徴 |
|---|---|---|
| クラウドETL/ELT SaaS | Fivetran、Stitch、Airbyte | 200+のコネクタを標準提供。設定だけで連携完了 |
| エンタープライズETL | Talend、Informatica PowerCenter | 大規模・複雑な要件に対応、オンプレ環境にも強い |
| オープンソース | Apache Airflow + dbt | カスタマイズ性が高く、コスト最適 |
| 国産ETL | ASTERIA Warp、Reckoner | 日本語サポート、国内システムとの親和性 |
| クラウドネイティブ | Google Dataflow、AWS Glue | クラウドリソースと密結合、サーバーレス |
| データ変換特化 | dbt(ELT前提) | SQL中心、バージョン管理・テストに強い |
各ツールのコスト体系・サポート品質・コネクタ数を詳しく比較したい場合は、データ連携ツールの選び方:コスト・サポート・コネクタ数で比較で国産・海外の主要10ツールをまとめています。

本記事では、ETLの基本概念からデータ基盤における役割までを解説しました。
ETLのポイント:
ETLはデータ基盤の「パイプライン」であり、データ活用の成否を左右する重要な要素です。適切なツールを選び、正しく設計・実装することで、データ活用の土台を固めることができます。そもそもなぜ今、企業にデータ活用への変革が求められているのかという背景は、なぜ今データマネジメントが必要なのか?DX成功の本質を解説で詳しく解説しています。
株式会社Evastでは、ETL/ELT設計からDWH構築、BIダッシュボード開発まで、一貫したデータ基盤構築を支援しています。
このようなお悩みがあれば、お気軽にご相談ください。現状診断からロードマップ策定までを伴走します。

SalesforceやkintoneなどのSaaSと社内DBを自動統合するETL/ELTツールを、運用体制・コスト体系・コネクタ要件の3軸で解説します。スモールスタートに向くtrocco、非エンジニア運用に強いASTERIA Warp、クラウドDWH連携重視のFivetranなど主要10ツールの選定ポイントを、Evastの現場経験をもとにまとめました。
ETLとELTの違いを、変換のタイミングと場所・処理性能・コスト構造・柔軟性・セキュリティの5つの軸で比較表つきで整理します。クラウドDWHとdbtの普及によりELTがModern Data Stackの主流になった背景、自社に合う方式を選ぶ判断基準、raw・staging・martのレイヤー設計などELT導入時の注意点まで、データ基盤の方式選定に悩む担当者向けに解説します。

データパイプラインとは、データを発生源から利用先まで自動で運び、使える形に整える処理の連なりです。ETLパイプラインとの違い(対立ではなく包含関係)、バッチ・ストリーミングなどの主要パターン、Airflowに代表されるオーケストレーション、監視・リトライ・冪等性という運用の要点までを図解つきで整理します。データ連携の自動化を検討し始めた担当者向けの入門記事です。

DWH(データウェアハウス)とは、分析専用に設計されたデータの集約場所です。通常のDB・データレイク・データマートとの違い、列指向ストレージの仕組み、BigQuery・Snowflake・Redshiftの選定ポイント、スタースキーマ・パーティション設計の基本、導入でよくある失敗まで、データ基盤の構築を検討している担当者向けに現場の視点でまとめました。