データ基盤とは?データベースとの違いもあわせて解説
データ基盤とは、企業内に散らばるデータを 収集・蓄積・加工・分析できる状態に整えるための仕組み全体 を指します。英語では Data Platform と呼ばれ、データ分析基盤・分析基盤と表記されることもあります。
一元管理の対象になるデータは、たとえば次のようなものです。
営業データ :売上、商談履歴、受注情報など顧客データ :CRM(顧客管理システム)、問い合わせ履歴などマーケティングデータ :広告出稿、Webアクセスログなど業務データ :在庫、製造、物流など外部データ :市場動向、競合情報、気象データなどこれらのデータは通常、部署ごとに別々のシステムで管理されています。営業はSalesforce、マーケティングはGoogle Analytics、経理は会計ソフト……というように、データが「サイロ化 」(部署ごとに分断された状態)しているわけです。
データ基盤は、このサイロを取り払い、組織全体が同じデータを同じ定義で参照・分析できる環境を提供します。
データベースとの違い 「データベースならすでにあるから十分では?」という疑問をよくいただきます。しかし、両者は役割がまったく異なります。
項目 データベース データ基盤 主な目的 業務データを正確に保存・更新する データを組織横断で分析・活用する データの範囲 1つのシステム内 複数システムを横断 主な利用者 業務アプリケーション 分析担当者・経営層・各部門 構成要素 DB単体 収集・蓄積・加工・可視化の一連の仕組み
ひと言でいえば、データベースは「データを安全に保存する箱」、データ基盤は「箱に入ったデータを取り出して使えるようにする仕組み全体」です。箱がいくつあっても、横断して使える状態になっていなければ分析はできません。
【導入すべき理由1】意思決定が速く、正確になる
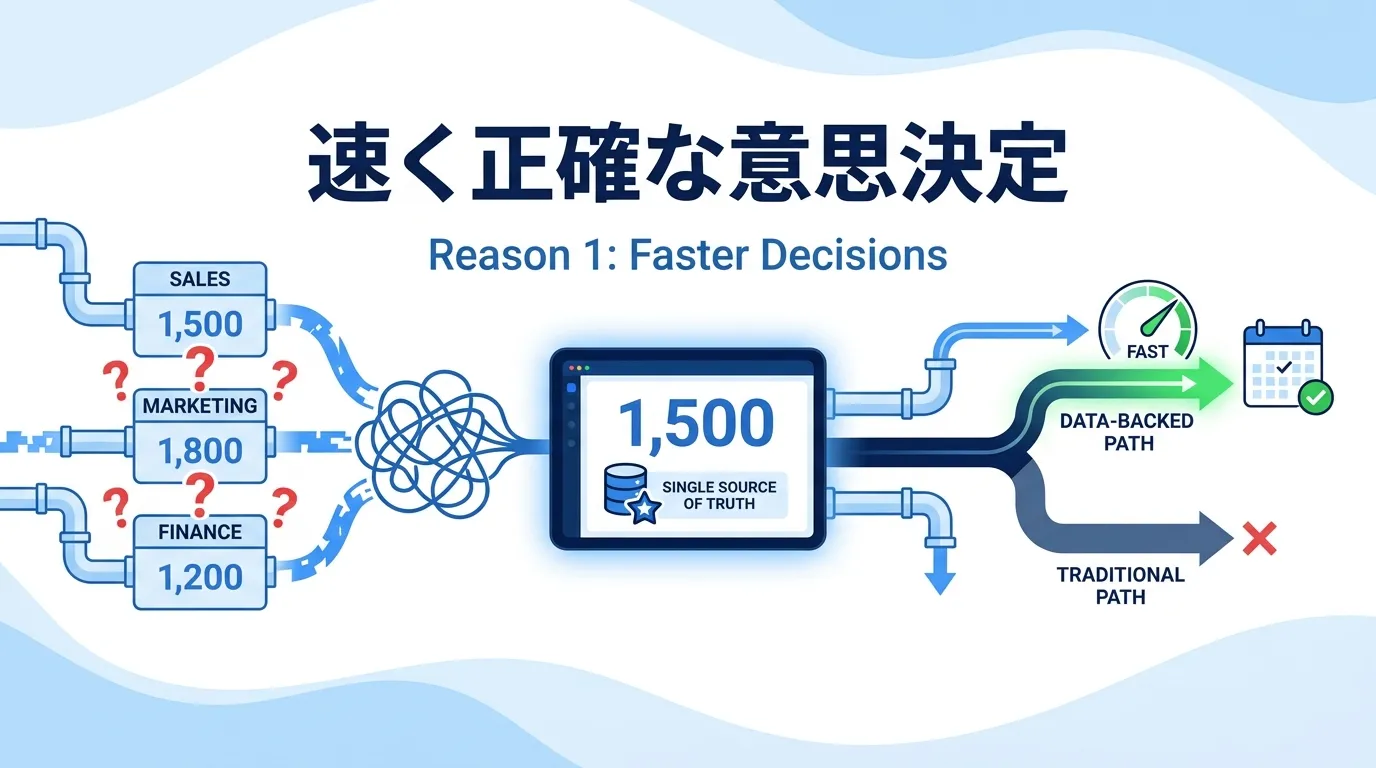
1つ目は、経営の判断に直結する価値です。データ基盤は、組織の意思決定を「正確に」かつ「速く」します。
経営会議の30分が「数字合わせ」に消えていないか データの分断は、そのまま議論の分断につながります。
経営会議で各部門が異なる数字を報告し、議論の前提が揃わない 営業とマーケティングで「リード」(見込み顧客)の定義が異なり、施策の評価が噛み合わない 「そのデータ、うちの部署からは見られません」という断絶が生まれる ある中堅メーカーでは、営業部門は「受注ベース」、経理部門は「入金ベース」でそれぞれ売上を集計していました。経営会議のたびに数字が食い違い、「どちらが正しいのか」という確認だけで毎回30分以上を費やしていたそうです。
数字の認識合わせに時間を取られる組織は、本質的な議論に入る前に消耗してしまいます。
Single Source of Truth が議論の前提を揃える データ基盤を整備すると、組織全体が「同じデータ・同じ定義・同じダッシュボード 」を共有できます。
Single Source of Truth(信頼できる唯一の情報源)の確立 データカタログ(社内のデータの定義や所在をまとめた台帳)による用語・指標定義の統一管理 会議冒頭の「数字の認識合わせ」が不要になる 先ほどのメーカーも、データ基盤の構築にあわせて「売上」の定義を統一した結果、不毛な確認作業は消滅しました。会議の時間は「なぜ売上が下がったのか」「どう改善するか」という本来の議題に使えるようになっています。
定義が揃うと、部門を横断した分析も可能になります。たとえばマーケティング施策の効果を、広告データ・Webアクセスデータ・営業の受注データを横断して追跡すれば、「どの施策が最終的な売上に貢献したのか」まで特定できます。各部門がバラバラのツールで数字を見ている状態では、この分析は成立しません。
経営ダッシュボードで判断のスピードを上げる 正確さに加えて、スピードも変わります。データ基盤とBIツール(データをグラフや表で可視化する分析ツール。Tableau、Power BI、Lookerなど)を連携させると、経営層が毎朝KPI(重要業績評価指標)を確認できる経営ダッシュボードを構築できます。
売上・粗利・受注残などの主要指標を日次で自動更新 異常値があればその日のうちに気づき、軌道修正できる 「月末の締め処理を待たないと数字がわからない」状態から脱却できる 問題の発見が月次から日次に変わるだけで、打ち手のスピードは大きく変わります。「先月のキャンペーンはどの顧客層に効いたのか」「値上げ後に解約率はどう動いたか」といった問いにも、勘と経験ではなく事実ベースで答えられるようになります。
なお、最初の経営ダッシュボードは、対象KPIを5〜10個程度に絞れば1〜2か月で形になります。最初から全指標を網羅しようとしないことが、定着への近道です。
💡 Evastの現場では :小売業・製造業を中心に20社以上のデータ基盤構築を支援してきましたが、導入後にまず変わるのは会議の風景です。「この数字、合ってる?」という確認が消え、開始10分で「で、どう動くか」の議論に入れるようになります。
【導入すべき理由2】データ業務のコストが下がる
2つ目は、日々の業務コストです。手作業の集計と属人化したレポート業務は、目に見えにくい人件費として組織の体力を奪い続けます。データ基盤は、この継続コストを仕組みの力で削減します。
集計だけで時間が溶けていく サイロ化が放置された企業では、次のような光景が日常になっています。
レポート作成のたびに、複数システムからCSVを手作業でダウンロードして結合する 同じ「顧客」でも部署によって定義が異なり、突き合わせに時間がかかる 同じデータを部署ごとに重複して管理している 「あのデータどこにある?」という問い合わせが情報システム部門に集中する データ分析の現場では、データの収集や集計、分析前の下準備に業務時間の大半を取られ、肝心の分析に使える時間がわずかしか残らない——という声は今も珍しくありません。
仮に月10時間の手作業集計を5つの部門がそれぞれ抱えていれば、年間600時間。人件費に換算すれば、決して無視できない金額になります。
一元管理と自動化で手作業を排除する 下の図のように、データ基盤はバラバラだったデータの流れを1本に束ねます。
導入前:データがサイロ化した状態
営業部門Salesforce
✕
マーケ部門GA4 / 広告管理
✕
経理部門会計ソフト
部署ごとに数字がバラバラ。突き合わせは手作業、定義も不統一
導入後:データ基盤で一元管理
→
データ基盤収集・蓄積・加工
→
全部門が同じ数字を参照Single Source of Truth
データサイロ状態とデータ基盤導入後の違い 一元管理が実現すると、現場では次の変化が起こります。
検索・集計の手間が激減する :必要なデータに数分でアクセスできる更新が自動で反映される :毎朝のバッチ処理(決まった時刻にまとめて実行される自動処理)で前日分まで揃った状態になる重複管理がなくなる :同じデータを部署ごとに別管理する無駄が消える「あの人がいないと数字が出ない」リスクも解消できる 工数だけでなく、属人化のリスクも隠れたコストです。Excelマクロや個人の手順メモに依存した集計業務は、次のリスクを抱えています。
業務の停滞 :担当者の休暇・退職で月次レポートが止まる品質のばらつき :人によって集計方法が微妙に違い、結果が再現できないナレッジの喪失 :異動や退職とともに「なぜこの計算式なのか」が失われる実際、担当者の退職を機に「誰も中身を説明できない集計Excel」だけが残り、作り直しに数か月かかったという例は珍しくありません。
データ基盤では、データの加工ルールをコードや設定として明文化し、システムが自動実行します。
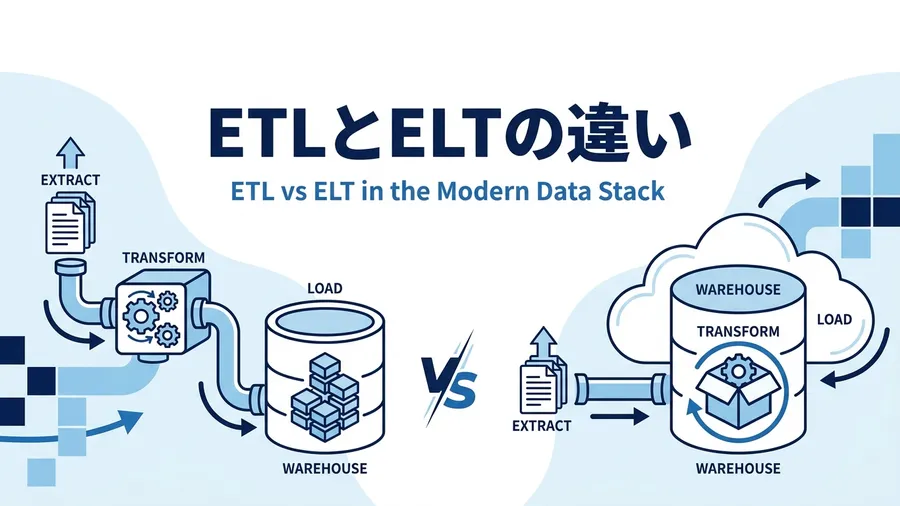
ETL/ELTによるデータ処理の自動化 :ETL/ELT(データの抽出・変換・転送を自動で行う仕組み)により、手作業のコピー&ペーストを排除する。近年はBigQueryやSnowflakeなどクラウドDWH(データウェアハウス:分析用にデータを集約して保管するデータベース)の処理能力を活かし、先にロードしてから変換する「ELT」パターンが主流です。両者の違いとELTが主流になった背景は、ETLとELTの違いとは?5つの比較軸とELTが主流になった理由 で詳しく解説していますダッシュボードのテンプレート化 :誰が開いても同じ定義・同じ見た目のレポートになる処理ルールの明文化 :加工ロジックがコードとして残り、組織のナレッジになる「誰がやっても同じ結果が出る」状態になれば、特定の個人に依存せず業務を改善し続けられます。月次レポート作成が3日から数時間に短縮されれば、浮いた時間を分析と改善に振り向けられるだけでなく、集計代行の外注費や引き継ぎにかかるコストの削減にもつながります。
【導入すべき理由3】AI活用など、将来の選択肢が広がる
3つ目は、将来への投資としての価値です。データ基盤は、AI・機械学習をはじめとする「次の打ち手」の前提条件になります。
AIプロジェクトの最初の壁は「データの準備」 生成AIブームを背景に「自社でもAIを使いたい」という相談は急増していますが、PoC(概念実証)の段階で止まってしまう企業が少なくありません。最大のボトルネックはモデルではなく、学習に使えるデータが整っていない ことです。
AIモデルの精度は、学習データの質と量に大きく依存します。データが各システムに散らばり、欠損や表記揺れだらけの状態では、どれだけ高性能なモデルを使っても期待した結果は得られません。
データ基盤がAI活用を現実にする 整備されたデータ基盤の上では、次のようなAI活用が現実的な選択肢になります。
需要予測 :過去の販売データから将来の需要を予測し、過剰在庫と欠品の両方を減らす顧客セグメンテーション :購買行動データに基づいて顧客を分類し、セグメント別に施策を打ち分ける異常検知 :製造データや取引データから異常パターンを検出するレコメンデーション :行動履歴に基づいて商品を提案する近年はBigQuery MLや各クラウドのAutoMLサービスのように、DWH上のデータに対してSQLベースで機械学習を試せる環境も整ってきました。基盤さえあれば、専任のAIエンジニアを抱えていなくても小さく実験を始められます。
スモールスタートでも、あとから広げられる 将来の選択肢は、AIに限りません。クラウド型のデータ基盤は、データ量や利用部門の増加に応じて段階的に拡張できます。最初は1つの部門・1つのユースケースで小さく始め、成果が見えた段階で対象データやダッシュボードを増やしていく——という育て方が可能です。
逆に、基盤がないまま個別ツールを継ぎ足してきた組織は、新しい打ち手を試すたびにデータの集め直しから始めることになります。順序を間違えないことが重要です。AIツールの選定より先に、データを集めて整える基盤づくりから始める——遠回りに見えて、これが最短ルートです。
データ分析基盤を支える4つの構成要素
ここまでの効果を生むデータ基盤(データ分析基盤)の中身は、機能別に見ると4つの要素に整理できます。次の図のように、データは「データソース → パイプライン → DWH → データマート → BIツール」という流れで処理されます。
※パイプラインはデータを自動で運ぶ処理の流れ、データマートはDWHから部門・用途ごとに切り出した分析用の小さなデータセットを指します。
このうちデータパイプラインの仕組みと運用の要点は、データパイプラインとは?ETLとの違いと仕組みを図解で解説 で詳しく解説しています。
データソース
パイプライン
DWH
データマート
BIツール
SalesforceCRM
GA4広告管理
基幹システムERP
IoT・センサー
BIツールTableau / Looker / Power BI
基幹システム、SaaS、Webサイト、IoTセンサーなど、さまざまなソースからデータを取得する工程です。
手法 :API連携(システム同士を直接つないでデータを受け渡す方式)・ファイル転送・ストリーミング(発生したデータをリアルタイムで送り続ける方式)代表的なツール :Embulk、Airbyte、Fivetranなど2. データ蓄積(Store):DWHに一元保管する 集めたデータを保管する工程です。中心になるのはDWH(データウェアハウス)で、Google BigQuery、Snowflake、Amazon Redshiftが代表的なサービスです。いずれもクラウド型で、データ量の増加に応じて柔軟に処理能力を拡張できます。
BigQueryを採用する場合の運用コストの考え方は、BigQueryのコスト最適化:運用で直面する課金トラップと対策 で詳しく解説しています。
生データを分析可能な形に変換する工程です。
クレンジング :欠損値の補完、異常値・重複の除去フォーマット統一 :日付形式や単位、表記揺れの統一統合 :複数ソースのデータをキーで結合するツールとしてはdbt、Dataform、Informaticaなどが使われます。中でもdbtの特徴と導入手順は、dbtとは?BigQueryのデータ変換を効率化するツールを解説 で紹介しています。収集と加工をつなぐETL/ELTの仕組みは、ETLの基礎解説記事 で詳しく扱っています。
4. データ可視化・分析(Visualize & Analyze):意思決定につなげる 加工済みのデータをダッシュボードやレポートとして可視化し、意思決定につなげる工程です。KPIダッシュボードの構築から、仮説検証のためのアドホック分析(必要に応じてその場で行う個別の深掘り分析)まで、Tableau、Power BI、Looker、Metabaseなどのツールが担います。
構成要素と代表ツールの一覧 4つの要素と代表的なツールを整理すると、次のとおりです。
構成要素 役割 代表的なツール・サービス 収集(Extract) 各システムからデータを取得する Fivetran、Airbyte、Embulk 蓄積(Store) DWHにデータを一元保管する BigQuery、Snowflake、Amazon Redshift 加工(Transform) 分析可能な形にデータを変換する dbt、Dataform、Informatica 可視化・分析 ダッシュボード・レポートで活用する Tableau、Power BI、Looker
すべてを一度に揃える必要はありません。最初のユースケースに必要な範囲で小さく構成し、利用の広がりに合わせて拡張していくのが現実的です。
データ基盤導入の注意点
メリットの大きいデータ基盤ですが、導入前に押さえておくべき注意点が3つあります。
データガバナンスの整備 基盤を作っても、データガバナンス(データを正しく安全に使い続けるための運用ルール)が整っていなければ、データの品質は維持できません。
データ品質 :誰が・どのタイミングで・どのようにデータを入力するかのルールアクセス権限 :誰がどのデータを見られるかの設計(個人情報・機密情報の保護)セキュリティ :データの暗号化、監査ログの取得特にアクセス権限の設計は後から直すと影響範囲が大きいため、構築の初期段階で決めておくことをおすすめします。
データ活用が頓挫する、よくある失敗パターン 現場で繰り返し目にする失敗には、共通点があります。
目的が曖昧なまま構築を始める :「とりあえずDWHを作ったが誰も使わない」状態に陥る最初から全社・全データを対象にする :要件が膨らみ、1年経っても何もリリースされない利用部門を巻き込まない :完成後に「欲しいデータと違う」と言われる運用体制を決めずに作る :障害対応やデータ追加の依頼先が宙に浮く対策はシンプルで、1〜2つのユースケースに絞って小さく始め、3〜6か月で最初の成果を出す ことです。スモールスタートで利用部門の信頼を獲得し、段階的に対象を広げる進め方が定着率を大きく左右します。
構築の前段となるデータ活用戦略の立て方については、データ戦略策定サービス もあわせてご覧ください。
運用コストへの意識 データ基盤は「作って終わり」ではありません。クラウドサービスの月額費用、データ量増加に伴うストレージ・クエリコスト、運用担当者の人件費など、継続的なコストが発生します。
目安として、クラウドDWHは従量課金が基本のため、スモールスタートであればインフラ費用は月数万円程度から始められます。ただし、データ量と利用者が増えるにつれてクエリコストは着実に膨らむため、無計画な全件スキャンを防ぐ設計やモニタリングが欠かせません。
導入前に3〜5年のTCO(総所有コスト)を試算し、得られる効果と比較しておくと、社内の承認プロセスも通しやすくなります。
まとめ:データ基盤は「攻め」のDXへの第一歩
企業がデータ基盤を導入すべき3つの理由を、あらためて整理します。
意思決定が速く、正確になる :Single Source of Truth で議論の前提が揃い、経営ダッシュボードで問題の発見が月次から日次に変わるデータ業務のコストが下がる :手作業集計と属人化を仕組みで解消し、レポート作成の工数・人件費・外注費を削減できるAI活用など、将来の選択肢が広がる :整ったデータが、AI・機械学習や新たな分析に挑戦するための土台になる経営の判断、日々の業務コスト、そして将来への投資。データ基盤の価値は、この3つの層にまたがります。単なる「守り」のIT投資ではなく、集計作業に費やしていた時間を分析と改善に振り向け、新たなビジネス価値を生み出すための「攻め」のDXへの第一歩です。なお、DXの成果がなぜ「データの扱い方」で決まるのかという背景は、なぜ今データマネジメントが必要なのか?DX成功の本質を解説 で詳しく解説しています。
まずは「どの業務の、どの判断を、データで速くしたいのか」というユースケースを1つ書き出すことから始めてみてください。対象が決まれば、必要なデータと構成は自然に絞り込めます。
データ基盤構築のご相談はEvastへ 株式会社Evastでは、データ基盤の設計・構築からBIダッシュボード開発、運用定着まで を一貫して支援しています。
「何から手をつければいいか、現状整理から相談したい」 「まずは小さく始めて、成果を見ながら拡大したい」 「将来のAI活用を見据えた構成にしたい」 このようなお悩みがあれば、お気軽にご相談ください。現状診断からロードマップ策定まで伴走します。
→ データ基盤構築サービスを見る 無料相談を申し込む