BigQueryにデータは蓄積できた。しかし「どのSQLが最新版か」「あの集計クエリは誰が書いたか」がわからない——そういった問い合わせを、データ担当者なら一度は経験したはずです。
変換SQLがスプレッドシートやSlack DMで共有され、誰も全体像を把握できていない状態は、BigQueryへの蓄積量が増えるほど悪化します。この問題に直接答えるツールが dbt(data build tool) です。

BigQueryにデータは蓄積できた。しかし「どのSQLが最新版か」「あの集計クエリは誰が書いたか」がわからない——そういった問い合わせを、データ担当者なら一度は経験したはずです。
変換SQLがスプレッドシートやSlack DMで共有され、誰も全体像を把握できていない状態は、BigQueryへの蓄積量が増えるほど悪化します。この問題に直接答えるツールが dbt(data build tool) です。

BigQueryにデータを蓄積しても、そのデータを「使える状態」に変換するSQL群の管理は別問題です。多くの現場で見られるのは、次のような状況です。
このような状態では、データの信頼性が担保できません。BigQueryにデータを入れること(ELTの「EL」部分)は解決できても、変換(T)の管理が追いつかずに「分析に使えないデータ基盤」が量産されます。データ基盤そのものの全体像や構成要素については、データ基盤とは?企業が導入すべき3つの理由と構成要素を解説で整理しています。
根本的な原因は、変換SQLがコードとして管理されていないことです。Gitで管理されていないSQLは、スクラッチ開発されたスクリプトと同じ問題を抱えます。誰が変更したか、いつ変更したか、なぜ変更したかが記録されません。

dbt(data build tool)は、BigQueryやSnowflakeなどのデータウェアハウス内でデータ変換をSQLファイルとして管理するオープンソースツールです。ELTプロセスの「T(Transform)」を担います。
ETLが変換処理を外部サーバーで行うのに対し、ELTではデータをDWHに先にロードし、DWH内部で変換します。dbtは後者のアプローチを採用しており、BigQueryの計算リソースを直接活用して変換処理を実行します。ETLとELTの詳しい違いは、ETLとは?データ統合の基礎と選定ポイントを解説をご参照ください。さらに、ELTがクラウド時代の主流になった経緯や自社に合う方式の選び方は、ETLとELTの違いとは?5つの比較軸とELTが主流になった理由で詳しく解説しています。
dbtには2つの提供形態があります。
| 項目 | dbt Core | dbt Cloud |
|---|---|---|
| 提供形態 | OSSのCLIツール | SaaS型のマネージドサービス |
| 費用 | 無料 | 有料(開発者1名あたり$50/月〜) |
| 実行環境 | ローカルまたは自前CI/CD | ブラウザ上のIDE + スケジューラー込み |
| 適合チーム | エンジニア中心で運用可能なチーム | 非エンジニアも含む混在チーム |
小規模なチームや検証フェーズでは dbt Core から始め、運用が本格化したら dbt Cloud に移行するケースが多いです。

dbtでは変換処理を「Model」と呼ぶ .sql ファイルとして定義します。1ファイル = 1テーブル(またはビュー)の原則でSQLを書くだけで、dbtが CREATE TABLE や INSERT を自動生成します。
ファイルがGitで管理されるため、「誰がいつ何を変えたか」がgit blameで追跡できます。レビューも通常のプルリクエストで行えるため、変更管理が自然とエンジニアリングの標準プロセスに乗ります。
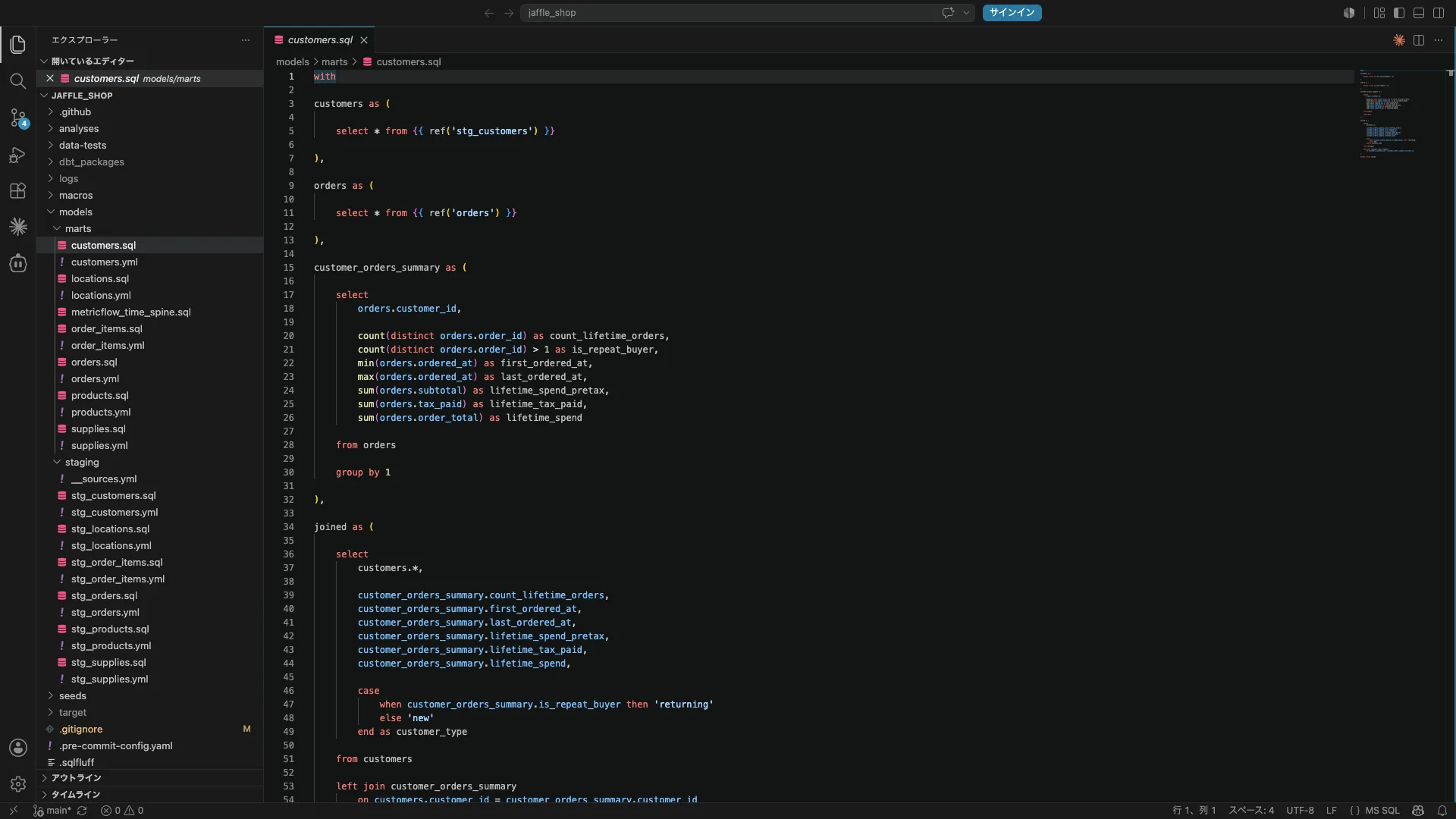
dbtの中核機能が ref() 関数です。あるModelから別のModelを参照する際に {{ ref('orders') }} と書くだけで、dbtが依存関係を自動でDAG(有向非巡回グラフ)として解析します。
この仕組みにより、「このテーブルを変えたら何が壊れるか」を事前に把握できます。dbtは依存関係の順番通りにModelを実行するため、手動での実行順序管理が不要になります。
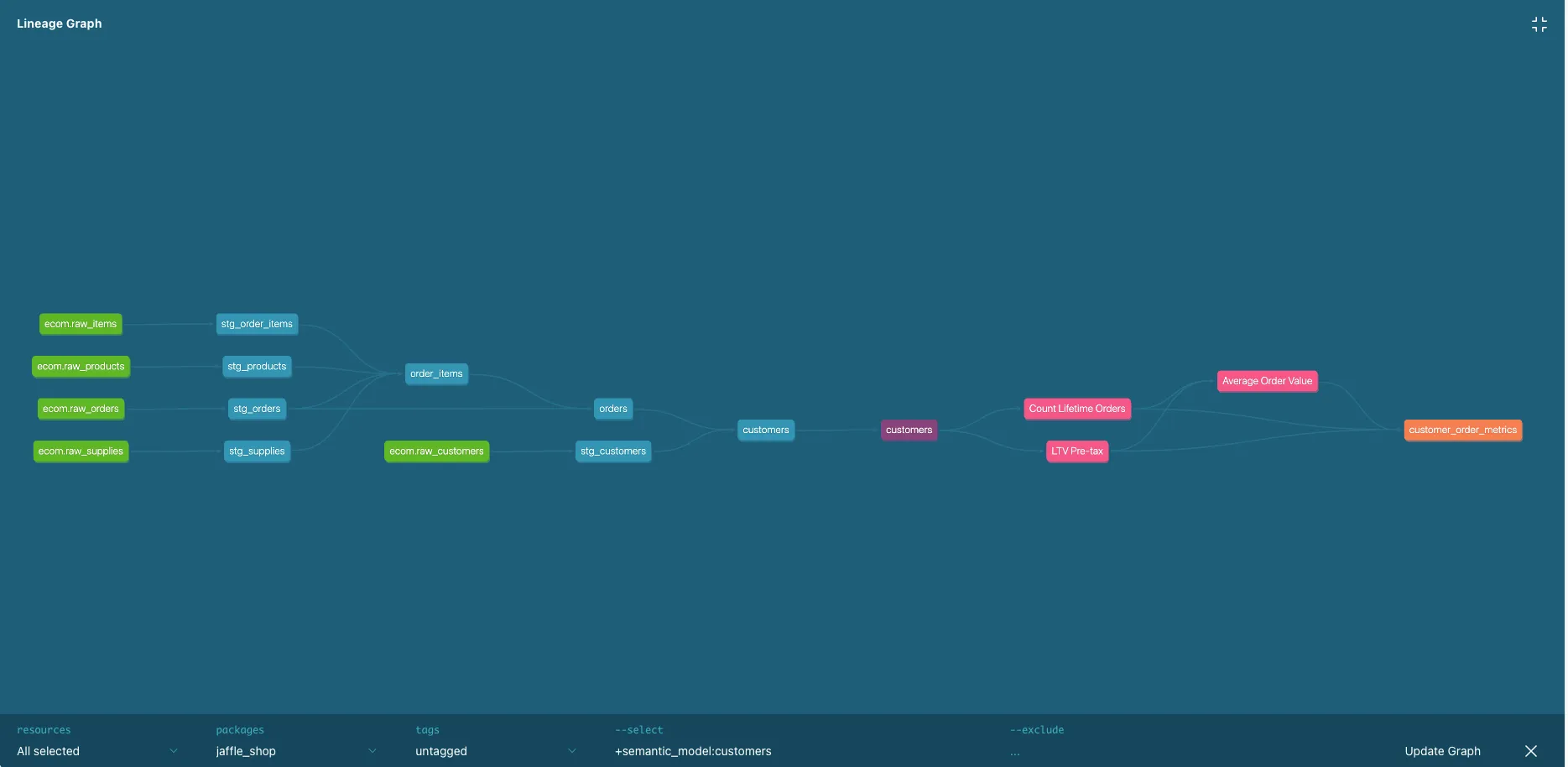
dbtでは schema.yml にテスト条件を宣言するだけで、データ品質チェックを自動化できます。標準テストとして以下が用意されています。
not_null:NULLが存在しないことを確認unique:主キーが一意であることを確認accepted_values:取り得る値の範囲を定義relationships:外部キー制約をデータレイヤーで担保テストの実行は dbt test の一行です。CI/CDに組み込めば、プルリクエスト時に自動でデータ品質チェックが走ります。
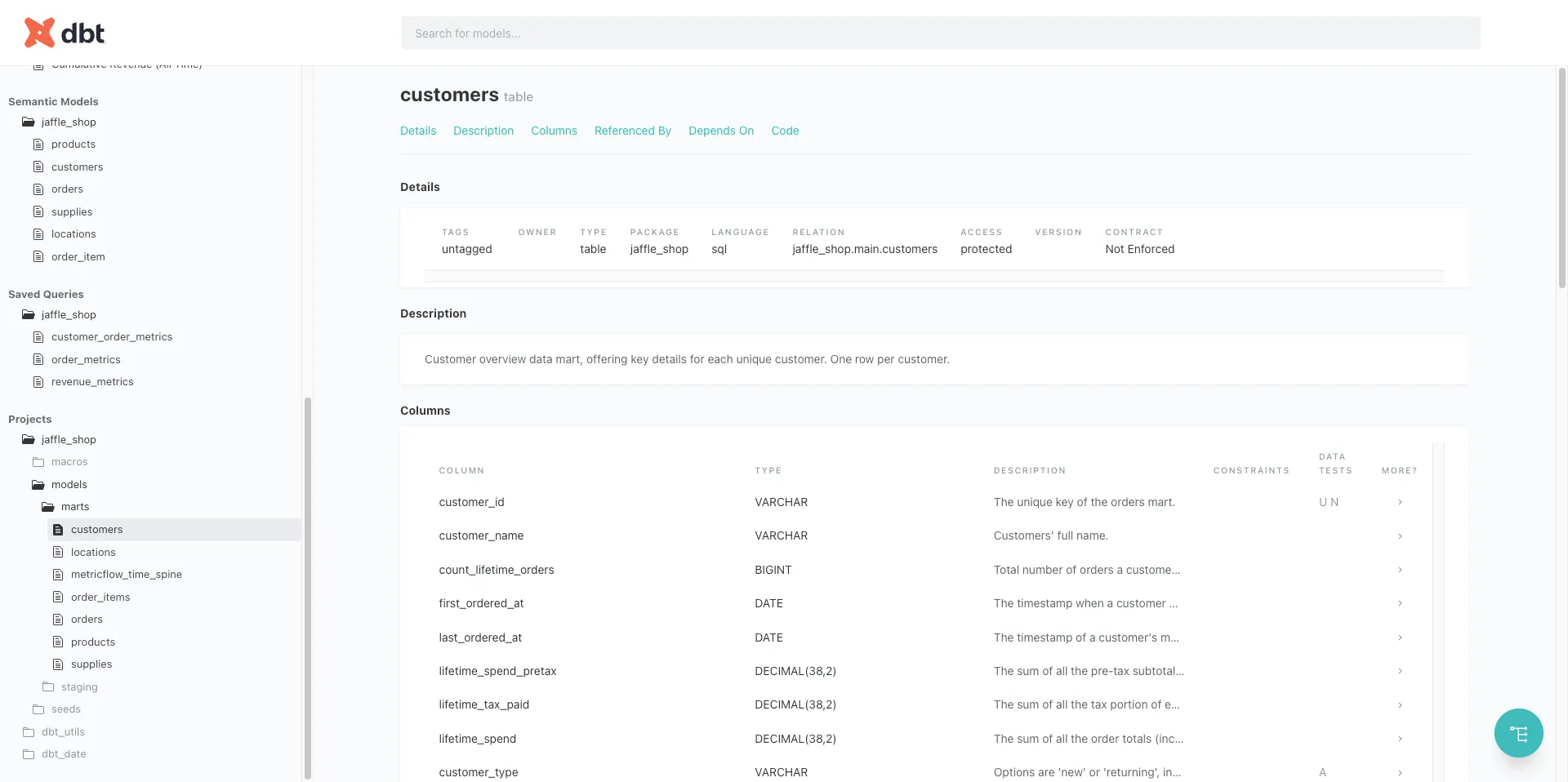
dbt docs generate コマンドを実行すると、Modelの定義・依存関係・テスト結果をまとめたデータカタログが自動生成されます。SQLのコメントと schema.yml の記述から作られるため、ドキュメントがコードと常に同期されます。
「このテーブルに何が入っているか」を確認するために担当者に聞き回る必要がなくなり、新しいメンバーのオンボーディング時間を大幅に短縮します。

dbt導入前後で、データチームの日常業務はどう変わるでしょうか。
Before:属人化・手作業・品質不明
After:Git管理・テスト自動化・依存関係の可視化
dbt test がCIで自動実行。品質問題はマージ前に検出目安として、3〜5名のデータチームで dbt を導入した場合、変換ロジックのレビュー時間が週あたり3〜5時間削減されるケースが多いです。また、データ品質起因の障害対応時間は、テスト自動化により 30〜50%短縮されます。

BigQueryとdbtの組み合わせが特に効果的な理由は、BigQueryのサーバーレスアーキテクチャにあります。BigQueryはクエリごとにコンピューティングリソースを動的にスケールするため、dbtが数十のModelを並列実行しても、インフラ側の設定変更なしに対応できます。
Evastが複数のBigQuery + dbtプロジェクトで得た知見として、dbtのマテリアライゼーション設定(view / table / incremental)をチューニングすることで、月間のBigQueryコストを30〜40%削減できた事例があります。頻繁に参照されるModelは table にキャッシュし、参照頻度の低いものは view のままにするだけでスキャン量が大幅に減ります。
実用的な構成例として、dbt + BigQuery + Cloud Scheduler を組み合わせた日次バッチアーキテクチャがあります。Cloud Schedulerが毎朝6時に dbt run を呼び出し、Modelが依存関係順に実行されます。dbt Cloud を使わなくても、この構成で十分な自動化が実現できます。
こうした日次バッチを含むデータパイプライン全体の設計や、オーケストレーション・監視といった運用の考え方は、データパイプラインとは?ETLとの違いと仕組みを図解で解説で扱っています。
まず、現在動いている変換SQLを洗い出します。BigQueryのScheduled Query、スプレッドシート内の集計式、アドホックなクエリを一覧化し、Modelファイルとして .sql に落とし込みます。
「完璧に移行してから使い始める」必要はありません。新規に作成するModelからdbtで管理し始め、既存ロジックは徐々に移行するアプローチが現実的です。
Modelファイルを作成したら、テーブル間の参照を ref() 関数に置き換えます。この作業を通じて、データの依存関係が可視化されます。循環参照(A → B → A のような構造)が発見されることもあり、長年気づかれなかったデータの問題が露出するケースもあります。
schema.yml に not_null や unique テストを定義し、dbt test でパスすることを確認します。同時に、カラムの説明文を schema.yml に記述することで、ドキュメントが自動生成されます。このステップまで完了すれば、データ基盤の「透明性」が格段に上がります。
目安期間:テーブル数20〜30程度の小規模構成であれば、ステップ1〜3の初期整備に 2〜4週間で基盤が整います。テーブル数100以上の大規模なデータ基盤では、段階的な移行を前提に 2〜3ヶ月を見ておくのが現実的です。
dbtの価値は「SQLが動く」ことではなく、「変換ロジックがチームで管理できる状態になる」ことです。BigQueryにデータが入っていても、変換ロジックが属人化していれば、データ基盤は実質的に機能しません。
ツールを入れるだけでデータ品質の問題が解決するわけではありません。dbtが提供するのは「管理できる環境」であり、そこにどのようなテストとロジックを定義するかはチームが設計する必要があります。
データ変換の管理が整うことで、新しい分析要件への対応速度が上がり、データへの信頼性が高まります。それが、データ基盤の本来の価値を引き出す第一歩です。
Evastでは、BigQuery + dbtを活用したデータ基盤の設計・構築を支援しています。
データ基盤の現状診断から導入支援まで、ご相談ください。
ETLとELTの違いを、変換のタイミングと場所・処理性能・コスト構造・柔軟性・セキュリティの5つの軸で比較表つきで整理します。クラウドDWHとdbtの普及によりELTがModern Data Stackの主流になった背景、自社に合う方式を選ぶ判断基準、raw・staging・martのレイヤー設計などELT導入時の注意点まで、データ基盤の方式選定に悩む担当者向けに解説します。

DWH(データウェアハウス)とは、分析専用に設計されたデータの集約場所です。通常のDB・データレイク・データマートとの違い、列指向ストレージの仕組み、BigQuery・Snowflake・Redshiftの選定ポイント、スタースキーマ・パーティション設計の基本、導入でよくある失敗まで、データ基盤の構築を検討している担当者向けに現場の視点でまとめました。

BigQueryを導入したのに月次請求が想定を大きく超えた——そんな経験を持つデータ担当者向けに、スキャン課金の仕組み、パーティション設計の重要性、SELECT *の罠、マートテーブルによる再利用、INFORMATION_SCHEMAによるコスト分析、Cloud Schedulerの設計を解説します。

データパイプラインのスケジューリング・依存管理・監視を担うオーケストレーションツールを4軸で比較します。Airflow(業界標準・大規模向け)、Dagster(データ資産中心・dbt親和性)、Prefect(シンプル・スモールスタート)の設計思想の違いと、チーム規模・技術スタックに応じた選び方をEvastの現場経験をもとに解説します。