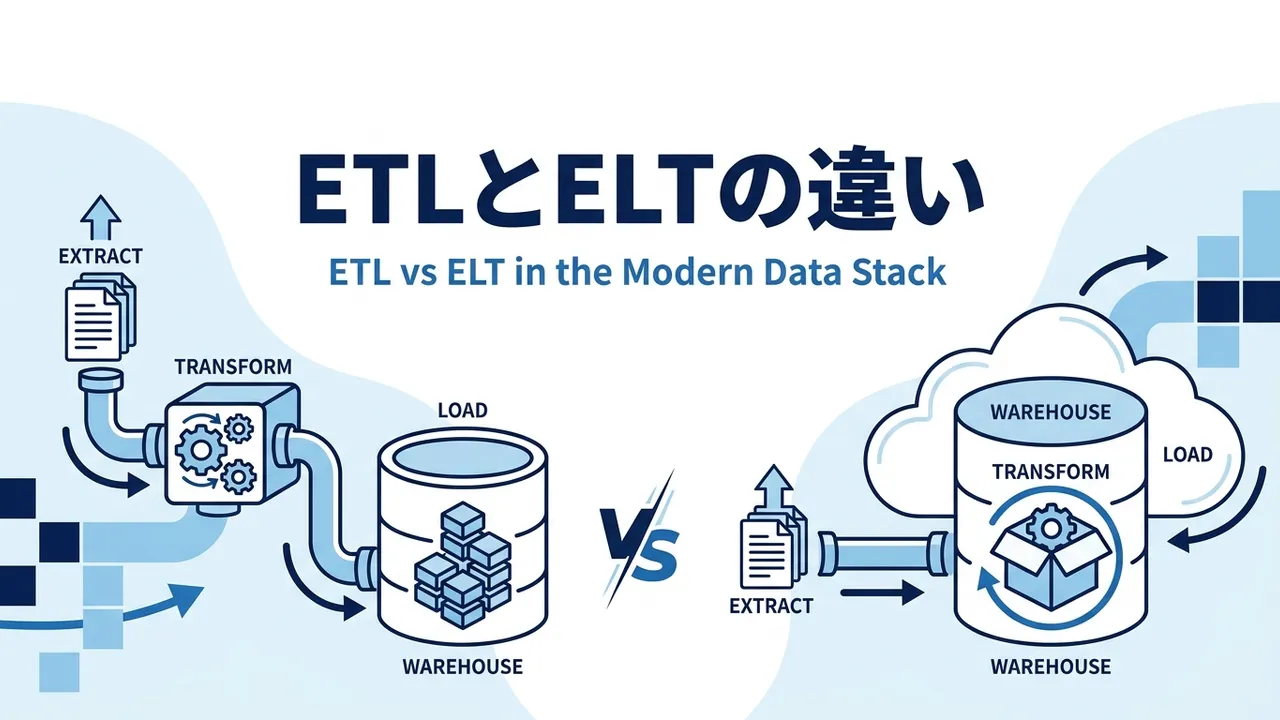
ETLとELTの基本:違いは変換を行う「順番」と「場所」

ETLとは:DWHに入れる「前」に変換する従来型の方式
ETLとは、Extract(抽出)・Transform(変換)・Load(格納) の頭文字を取った言葉です。複数のシステムからデータを抜き出し、ETLツールや専用サーバーの上で分析に適した形へ変換してから、DWH(データウェアハウス。分析用にデータを集約しておくデータベース)に格納します。DWHそのものの仕組みやクラウドDWHの比較についてはDWH(データウェアハウス)とは?データレイク・データマートとの違いを解説で整理しています。
ELTとは:DWHに入れた「後」にSQLで変換するクラウド時代の方式
一方のELTは、同じ3つの工程を「Extract → Load → Transform」の順で行います。抽出したデータをまず生のままDWHに格納し、変換はDWHの内部でSQLを使って実行する方式です。
次の図のように、両者の差は工程の中身ではなく、TransformとLoadの順番——つまり変換を担う場所にあります。
ETL(従来型)
Extract
→
TransformETLツール内で変換
→
DWHへLoad
ELT(クラウドDWH時代)
Extract
→
DWHへLoad生データのまま
→
TransformSQL / dbt で変換
ETLでは変換の主役がETLツールとその実行サーバーであるのに対し、ELTでは変換の主役がDWH自身に移ります。
後述する性能・コスト・柔軟性の差は、すべてこの一点から派生します。
なお、ETLそのものの仕組みや代表的なツールはETLの基礎解説記事で図解つきで詳しく扱っています。このページでは「両者の違いと使い分け」に絞って進めます。
ETLとELTの5つの違いを比較表で整理

両者の違いを、「変換のタイミングと場所」「処理性能とスケーラビリティ」「コスト構造」「柔軟性・再利用性」「セキュリティ・ガバナンス」という5つの軸で比較します。まず全体を表で俯瞰してから、各項目を掘り下げます。
| 比較軸 | ETL | ELT |
|---|
| 変換のタイミングと場所 | DWHに入れる前、ETLツール上で変換 | DWHに入れた後、DWH内部で変換 |
| 処理性能とスケーラビリティ | ETLサーバーの性能が上限 | クラウドDWHの並列処理で拡張しやすい |
| コスト構造 | ツールライセンス+変換サーバーの維持費 | DWHのストレージ+クエリの従量課金 |
| 柔軟性・再利用性 | 変換後のデータのみ保持、やり直しは再抽出 | 生データを保持し、何度でも変換し直せる |
| セキュリティ・ガバナンス | DWH投入前にマスキングなどの加工が可能 | 生データがDWHに入るため権限設計が必須 |
【違い1】変換のタイミングと場所:ETLは「DWHの手前」、ELTは「DWHの中」
ETLでは、データはETLツールの中で加工が完了してからDWHに届きます。DWHに入る時点で「きれいなデータ」だけが存在する状態です。
ELTでは、データソースの内容がほぼそのままDWHにコピーされ、その後にSQLで加工されます。DWHの中に「生データ」と「加工済みデータ」が共存するため、設計の自由度が上がる反面、整理整頓の責任もDWH側に移ります。
【違い2】処理性能とスケーラビリティ:ELTはDWHの並列処理を使い切れる
ETLの処理性能は、変換を実行するETLサーバーのCPU・メモリが上限になります。データ量が増えるたびにサーバー増強が必要で、スケーラビリティ(データ量の増加に応じて処理能力を拡張できる性質)の面では分が悪い構造です。
ELTの変換はBigQueryやSnowflakeといったクラウドDWHが実行します。これらは数千台規模のマシンで処理を分散する設計のため、数億行のテーブル同士の結合・集計も数十秒〜数分で完了することが珍しくありません。
Evastの現場でも、日次5,000万行規模の広告ログ基盤をETLサーバーでの変換からBigQuery内での変換に切り替えた結果、夜間4時間かかっていたバッチが20分前後まで短縮された例があります。
【違い3】コスト構造:ETLは固定費中心、ELTは従量課金中心
ETLは、ツールのライセンス費用(エンタープライズ製品では年間数百万円規模のものもあります)と、変換サーバーの維持費という固定費が中心です。データ量が少なくても一定のコストがかかります。
ELTは、DWHのストレージ料金と計算リソースの従量課金が中心です。課金の単位はDWHごとに異なり、BigQueryのオンデマンド料金はクエリがスキャンしたデータ量に、Snowflakeは仮想ウェアハウス(クエリを処理する計算リソースの単位)の稼働時間に応じて課金されます。
ストレージはBigQueryで1GBあたり月数円程度と安いため、小さく始めて使った分だけ払う形にできます。ただし後述のとおり、計算側の課金は設計を誤ると膨らみやすい点に注意が必要です。
【違い4】柔軟性・再利用性:生データを残すELTは「やり直し」に強い
ETLでは変換後のデータしかDWHに残らないため、「集計の粒度を変えたい」「半年前のデータを別の切り口で見たい」となったとき、変換ロジックを直してデータソースから再抽出するしかありません。元システム側でログが消えていれば、復元は不可能です。
ELTは生データをDWHに保持しているので、SQLを書き直して再実行すれば、過去にさかのぼって何度でも変換をやり直せます。分析要件が頻繁に変わる組織ほど、この差が効いてきます。
【違い5】セキュリティ・ガバナンス:DWHに入れる前に加工できるのはETL
ガバナンス(誰がどのデータにアクセスできるかを統制する管理ルール)の観点では、ETLに分があります。DWHに入れる前にマスキング(個人名などを伏せ字に置き換える処理)や不要列の除外ができるため、「個人情報をDWHに置かない」という方針を構造的に守れるからです。
ELTでは生データがそのままDWHに入るため、raw層へのアクセス権限の絞り込みや、カラム単位のマスキング設定など、DWH側での権限設計が必須になります。クラウドDWHにはこうした機能が標準で備わっていますが、「設定する人と運用ルール」を用意しないと機能しません。
Modern Data StackでELTが主流になった3つの背景

Modern Data Stack(クラウドサービスを組み合わせて構成する現代型のデータ基盤パターン)では、ELTが事実上の標準になっています。FivetranやTROCCOでデータを運び、BigQueryやSnowflakeに貯め、dbtで変換する——この組み合わせはすべてELT前提の設計です。
ETLが劣っていたから置き換わったのではなく、2010年代に進んだ技術変化がELTの弱点を消し、強みを際立たせました。背景は大きく3つあります。
【ELT普及の背景1】クラウドDWHの性能向上と低価格化:「とりあえず全部入れる」が許される時代に
ELT普及の最大の推進力は、BigQuery(2011年に一般提供開始)、Amazon Redshift(2013年)、Snowflake(2015年)に代表されるクラウドDWHです。
従来のオンプレミスDWHは、ハードウェア導入に数千万円かかるうえ容量も固定で、「生データを全部入れる」という発想自体が非現実的でした。だからこそ、DWHに入れる前に変換して容量を節約するETLが合理的だったのです。
クラウドDWHはこの前提を覆しました。
鍵になったのが「ストレージとコンピュートの分離」、つまりデータの保管領域と計算リソースを別々に拡張・課金できる仕組みです。保管は安価に大量に、計算は必要なときだけ強力に使えるため、「先に全部入れて、あとからDWHの計算力で変換する」ELTが経済的にも性能的にも合理的になりました。
【ELT普及の背景2】dbtの登場:SQLの変換ロジックを「開発」として管理できるようになった
ELT最大の課題は、DWH内に書き散らかされるSQLが無法地帯になりやすいことでした。この課題を解決したのが、2016年に米Fishtown Analytics(現dbt Labs)がオープンソースとして公開した dbt です。
dbtを使うと、SQLの変換ロジックをGitでバージョン管理し、テストを自動実行し、テーブル間の依存関係を可視化できます。「SQLを書ける人なら誰でも、ソフトウェア開発と同じ品質管理のもとで変換処理を作れる」状態になり、ELTの実用性が一気に高まりました。dbtの詳細はdbtの解説記事で扱っています。
【ELT普及の背景3】FivetranやTROCCOなど「運ぶだけ」のツールが成熟した
変換をDWHに任せられるなら、データ転送ツールは「抽出して運ぶ」ことに専念できます。この割り切りで成功したのがFivetranやAirbyteで、SalesforceやGoogle Analyticsなど数百種類のコネクタを使い、ノーコードで数時間後にはDWHへのデータ連携が動き始めます。
国内でも、TROCCOが広告媒体や国産SaaSへの対応と日本語サポートを強みに広く使われています。「転送はSaaSに任せ、変換はdbtで書く」という分業が確立したことで、ELTは少人数のデータチームでも運用できる現実的な選択肢になりました。Fivetran・trocco・Airbyte・ASTERIA Warpなど主要ツールをコスト・サポート・コネクタ数の3軸で比較した詳細は、データ連携ツールの選び方:コスト・サポート・コネクタ数で比較をご覧ください。
ETLとELT、どちらを選ぶべきか?4つの質問で判断する
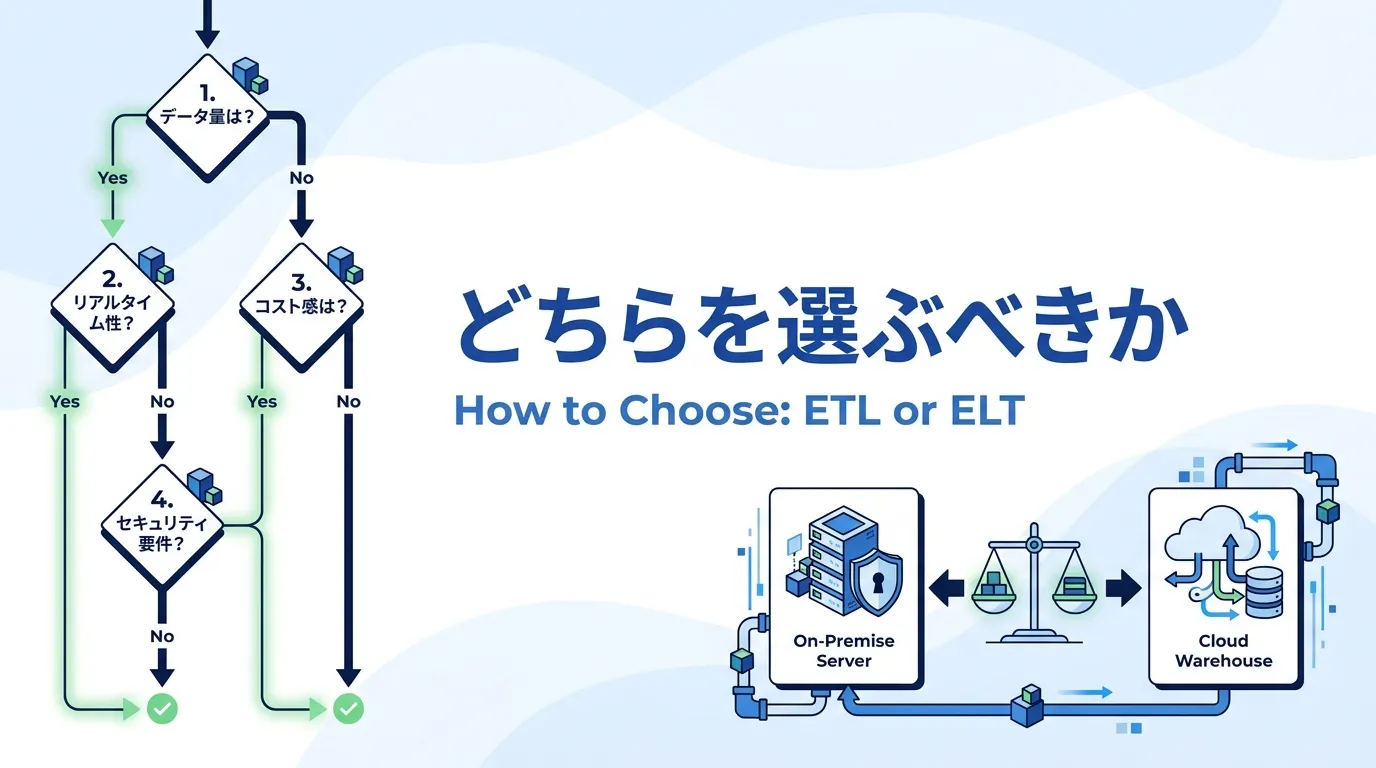
主流はELTとはいえ、すべての企業にELTが向くわけではありません。前章の5つの違いのうち、方式選定を実際に左右しやすいのは「セキュリティ・ガバナンス」「処理性能」「柔軟性」の3つです。これに連携先システムの事情を加えた、次の4つの質問に順に答えると、自社に合う方式が見えてきます。
- 生データをDWHに置けない制約(法規制・社内規程)があるか? → YES なら、DWH投入前に加工できる ETL(または投入前マスキングとの併用)
- データ量は今後も増え続ける見込みか? → YES なら、DWHの計算力で拡張できる ELT
- 分析の要件・切り口は頻繁に変わるか? → YES なら、生データからやり直せる ELT
- 連携先はオンプレミスの基幹システムが中心か? → YES なら、実績あるETLツールの方が接続性で有利な場合が多い
質問1は違い5(セキュリティ・ガバナンス)、質問2は違い2(処理性能)、質問3は違い4(柔軟性)にそれぞれ対応します。質問4だけは5つの違いではなくツールの成熟度の話です。なお、コスト構造(違い3)は方式を決めた結果としてついてくる面が大きいため、質問で絞り込んだ後に試算する項目と考えてください。
それぞれの方式が向くケースをまとめると、次のようになります。
ETLが向くケース:
- 個人情報・機微情報をDWHに生のまま置けない
- オンプレミスのレガシーシステムとの連携が中心
- データ量が小さく、分析要件もほぼ固定されている
ELTが向くケース:
- 大量データ(目安として日次数百万行以上)を扱う
- 分析要件が頻繁に変わり、過去データの再集計が多い
- SQLを書けるメンバーがいて、データの民主化(エンジニア以外の社員も自分でデータを扱える状態)を進めたい
なお、実務では二者択一にしないケースも多くあります。Evastのプロジェクトでも、文字コード変換や個人情報の除外といった最低限の加工だけ転送ツール側で行い、ビジネスロジックを含む変換はdbtでDWH内に寄せる、というハイブリッド構成が定番です。
重要なのは「変換ロジックの本体をどこに集約するか」を最初に決めておくことです。
ETL/ELTを含むデータパイプライン全体の考え方や、バッチ/ストリーミングというもう1つの分類軸については、データパイプラインとは?ETLとの違いと仕組みを図解で解説で図解つきで整理しています。
ELT導入時の注意点:レイヤー設計とコスト管理が成否を分ける

ELTは「とりあえず全部DWHに入れられる」手軽さが魅力ですが、その手軽さが裏目に出る失敗も現場では頻繁に見かけます。導入時に押さえるべきポイントは3つです。
生データとマートの乱立を防ぐ:raw・staging・martの3層で管理する
ELT導入企業でもっとも多い失敗が、テーブルの無秩序な増殖です。実際に、運用開始から半年でテーブルが300個を超え、「売上の正しい集計がどれなのか誰もわからない」状態に陥った基盤の立て直しを支援したこともあります。
予防策は、レイヤードアーキテクチャ(データを役割ごとの層に分けて管理する設計)の採用です。図のように、DWH内をraw・staging・martの3層に分け、テーブル名の接頭辞で層を明示します。
データソースSaaS / DB / ログ
→
クラウドDWHの内部
raw層raw_◯◯
生データのまま保管
→
staging層stg_◯◯
型変換・クレンジング
→
mart層mart_◯◯
集計済み・分析用
→
BIツールダッシュボード
- raw層(raw_):データソースの生データをそのまま保管。手を加えない
- staging層(stg_):型変換・名寄せ・クレンジングを済ませた中間データ
- mart層(mart_):データマート(特定の分析用途向けに集計済みのテーブル群)。BIツールが参照するのはこの層だけ
従来型の構成にあてはめると、raw層がデータレイク(生データを加工せず安価に貯めておく置き場)、mart層がデータマートに相当します。かつては別々のシステムとして組んでいたこの3層を、ELTではDWH内部のレイヤーとして実現するわけです。
なお、同じ3層をDWH内部の「データレイク層・データウェアハウス層・データマート層」と呼ぶ流派もあります(『実践的データ基盤への処方箋』など日本の書籍でよく使われる命名です)。名前は違っても、役割分担はraw・staging・martとほぼ同じと考えて差し支えありません。
「BIや業務部門が触ってよいのはmart層のみ」と決めるだけでも、数字の食い違いと重複テーブルの大半は防げます。
クエリ課金を暴走させない:コスト管理は設計段階から組み込む
ELTでは変換や分析のクエリを実行するたびにDWHの計算コストが発生し、無対策だと月額費用が想定の数倍に膨らむことがあります。とくにBigQueryのオンデマンド料金はクエリがスキャンしたデータ量に応じた課金のため、生データへの全件クエリを毎日回すような使い方は禁物です。
mart層の集計テーブルを参照させる、テーブルを日付で分割するといった設計面の対策が有効です。具体的なテクニックはBigQueryのコスト最適化記事にまとめています。
raw層には個人情報が眠る:アクセス権限の設計を後回しにしない
生データを丸ごと取り込むELTでは、raw層に顧客の氏名・メールアドレスなどが含まれがちです。raw層へのアクセスをデータチームの数名に限定する、個人情報カラムにはDWHのマスキング機能を適用するといった権限設計を、運用開始前に済ませておきましょう。
「あとで整備しよう」と先送りした結果、全社員が生の顧客データを参照できる状態で監査の指摘を受ける——というのは、決して珍しくない失敗です。
まとめ:違いの本質は「変換の場所」、選ぶ基準は「ビジネス要件」
ETLとELTの違いと、ELTが主流になった理由を整理しました。要点は次の5つです。
- 違いの本質:変換をDWHの手前で行うのがETL、DWHの中で行うのがELT
- 5つの比較軸:変換の場所・処理性能・コスト構造・柔軟性・セキュリティで両者の向き不向きが分かれる
- ELTが主流になった背景:クラウドDWHの性能向上と低価格化、dbtの登場、転送特化ツールの成熟
- 選び方:生データの取り扱い制約・データ量・要件の変化頻度・連携先で判断。ハイブリッドも有力
- ELTの注意点:raw・staging・martのレイヤー設計、クエリコスト管理、権限設計を最初に固める
方式の選択はあくまで手段であり、出発点は「何のためにデータを使うのか」というビジネス要件です。要件を整理したうえで、自社のデータ量・体制・制約に合った方式を選んでください。この「何のためにデータを使うのか」を経営の視点から整理する考え方については、なぜ今データマネジメントが必要なのか?DX成功の本質を解説もあわせてご覧ください。
ETL/ELTの方式選定・データ基盤構築のご相談はEvastへ
株式会社Evastでは、ETL/ELTの方式選定からDWH構築、dbtによる変換パイプライン整備、BIダッシュボード開発まで、一貫したデータ基盤構築を支援しています。
- 「既存のETL基盤をELTに移行すべきか判断したい」
- 「ELTを導入したが、テーブルが乱立して管理しきれない」
- 「Modern Data Stackでデータ基盤をゼロから設計したい」
このようなお悩みがあれば、お気軽にご相談ください。現状診断からアーキテクチャ設計、移行計画の策定までを伴走します。
→ データ基盤構築サービスを見る → 無料相談を申し込む